02.Agent思考框架-CoT思维链
AI智能体思考框架主要是为了赋予AI智能体结构化的推理和决策能力,为AI智能体提供一套完整的方法论,指导其如何理解目标、分解任务、运用工具、处理输入,并依据环境反馈来调整资深行为
当前主流的思考框架有CoT, ReAct, ToT, Plan-and-Execute,本文将主要介绍一下CoT 思维链
1.CoT思维链
Chain-of-Thought(CoT) 来源与论文 《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》
论文中提出,CoT核心是让大模型在输出最终答案前,先用自然语言生成一步步的推理过程,就像人类解数学题时写 “解题步骤”、做决策时列 “思考清单” 一样。而这些推理的中间步骤就被称为思维链
1.1 CoT定义
以下内容,可来自于论文: Igniting Language Intelligence: The Hitchhiker's Guide From Chain-of-Thought Reasoning to Language Agents
区别于传统的 Prompt 从输入直接到输出的方式,CoT完成了从输入到思维链再到输出的转变,即
由 input -> output 转变为 input -> reasoning chain -> output

如图,一个完整的包含CoT的提示词,通常由指令(Instruction), 逻辑依据(Rationale), 示例(Examplars)三部分组成
- 指令: 用于描述问题并且告知大模型的输出格式
- 逻辑: 依据即指 CoT 的中间推理过程,可以包含问题的解决方案、中间推理步骤以及与问题相关的任何外部知识,
- 示例: 则指以少样本的方式为大模型提供输入输出对的基本格式,每一个示例都包含:问题,推理过程与答案。
以是否包含示例为区分,可以将 CoT 分为 Zero-Shot-CoT 与 Few-Shot-CoT
在上图中,Zero-Shot-CoT 不添加示例而仅仅在指令中添加一行经典的“Let's think step by step”,就可以“唤醒”大模型的推理能力。
而 Few-Shot-Cot 则在示例中详细描述了“解题步骤”,让大模型参考样例进行执行,从而得到推理能力。
1.2 CoT的作用
- CoT允许模型把一个复杂问题拆解成多个步骤,也就是说需要更多推理步骤的问题可以多分点计算量。
- CoT提供了一个观察模型为何会犯错的窗口,给观测者了解模型出现幻觉的原因
- CoT能用在数学应用题、常识推理和符号操作上,也就有可能用在任何人类通过语言能解决的问题上
- CoT支持任何语言模型使用
1.3 CoT的优势
- 提高推理性能:CoT 通过将复杂问题分解为多步骤的子问题,相当显著的增强了大模型的推理能力,也最大限度的降低了大模型忽视求解问题的“关键细节”的现象,使得计算资源总是被分配于求解问题的“核心步骤”;
- 提高可解释性:对比向大模型输入一个问题大模型为我们仅仅输出一个答案,CoT 使得大模型通过向我们展示“做题过程”,使得我们可以更好的判断大模型在求解当前问题上究竟是如何工作的,同时“做题步骤”的输出,也为我们定位其中错误步骤提供了依据;
- 提高可控性:通过让大模型一步一步输出步骤,我们通过这些步骤的呈现可以对大模型问题求解的过程施加更大的影响,避免大模型成为无法控制的“完全黑盒”
- 提高灵活性:仅仅添加一句“Let's think step by step”,就可以在现有的各种不同的大模型中使用 CoT 方法,同时,CoT 赋予的大模型一步一步思考的能力不仅仅局限于“语言智能”,在科学应用,以及 AI Agent 的构建之中都有用武之地
2. CoT原理
2.1 CoT生效原理
大模型是如何支持CoT的呢?
本质是 大模型支持 CoT 的本质,是通过训练或提示机制,使模型在生成过程中显式或隐式地产生中间推理步骤,从而提高复杂推理任务的可解释性与准确性。
2.1.1 提示级CoT:基于提示工程的显式引导
最早、也是目前最常用的方式。其核心思想是不改变模型参数,而是通过提示语(prompt)设计,引导模型在推理过程中显式输出中间步骤。主要分为两类:
- 零样本 CoT(Zero-shot CoT):仅在问题末尾添加引导语,例如
Let’s think step by step或请先分析步骤,再给出结论。- 例如,问题“为什么夏天海滩人多?” 加上引导语后
- 模型会生成类似推理链:
- 第一步,夏天天气炎热,人们倾向于去水边避暑;
- 第二步,海滩具备娱乐与降温功能;
- 第三步,夏季假期增加出行需求”,最后得出结论“因此夏天海滩更受欢迎。
这种方式简单有效,但在复杂推理任务中的准确率较低,对模型语言偏好和训练语料敏感。
少样本 CoT(Few-shot CoT):在提示中提供若干
问题 + 推理链 + 答案- 示例,使模型通过上下文学习(In-context Learning, ICL)模仿推理模式。
- 例如在算术任务中提供示例:「问题:10 个橘子吃了 3 个,还剩几个?→ 推理:10−3=7 → 答案:7」。模型据此可类推新问题。
这种方式能显著提升推理稳定性,但需要人工构建高质量示例。
2.1.2 自举式CoT:利用模型自身能力自动生成示例
人工编写少样本示例成本高,因而出现了 自动思维链(Auto-CoT) 方法。其核心思想是:让模型通过自举(bootstrapping)机制自动生成用于提示的 CoT 示例。典型流程如下:
- 问题聚类(Question Clustering):将待解决任务划分为若干语义相近的类别(如“加法”“减法”“应用题”)。
- 自动示例生成(Automatic Demonstration Generation):从每类中选择代表性问题,利用零样本 CoT 生成高质量推理链作为示例。
- Few-shot 提示重构:将自动生成的示例嵌入提示中,引导模型处理同类问题。
在实践中,Auto-CoT 常与 自一致性(Self-consistency) 策略结合,即采样多条思维链并选取最一致的答案,以减轻错误推理传播问题。 这种方法减少人工干预,能在无需重新训练的前提下,自动获得较强的推理能力。
2.1.3 模型级 CoT:在训练阶段内化推理能力
现在的大模型(如 DeepSeek-R1、GPT-o1 等)已不再依赖提示引导,而是通过训练过程直接“内化”思维链能力。实现路径通常包括以下几个阶段:
- 监督微调(Supervised Fine-tuning, SFT)阶段:在训练数据中引入大量包含“推理步骤 + 最终答案”的样本,使模型学习生成中间思考过程;
- 强化优化(RLHF / RLAIF)阶段:通过人类反馈或自动反馈信号,奖励“逻辑正确、步骤完整”的推理链,惩罚“跳步或错误推理”;
- 过程监督(Process Supervision)与验证器机制(Verifier-based Fine-tuning):进一步强化中间推理过程的可验证性,使模型学会自我审查与修正。
经过这样的训练,模型在面对复杂推理任务时,即便没有显式提示,也能自然生成符合逻辑的思维链,表现出“内置的推理习惯”。
2.1.4 多模态 CoT:跨模态推理的思维链扩展
随着多模态大模型的发展(如 GPT-4o、Gemini 2等),CoT 概念已扩展至文字与视觉等多源信息的联合推理。
多模态 CoT(Multimodal CoT) 旨在让模型在生成答案前,整合图像特征与文本上下文,形成跨模态的推理链。
例如,输入一张“拥挤的海滩”图片并询问“夏天这里会更受欢迎吗?”,模型可能推理:“图片显示人群密集,当前已受欢迎;夏季天气炎热,人们更倾向于去海滩避暑;假期增多会进一步提升出游人数”,最终得出结论“夏天会更受欢迎”。
技术上,多模态 CoT 通过两类机制实现:
- 融合式推理(Fusion-based Reasoning):将图像与文本 token 在同一 Transformer 层中联合建模;
- 递归式推理(Iterative Reasoning):先生成初步视觉分析,再结合语言模型多轮细化推理。
这类机制显著提升了模型在视觉问答(VQA)、图文逻辑、视频理解等任务中的推理一致性与可解释性。
2.1.5 小结
CoT 的演进体现了从“显式提示驱动”到“内化思维模式”的范式转变:
- 提示级 CoT:通过设计输入引导模型逐步推理;
- 自举式 CoT:让模型利用自身能力自动生成推理示例;
- 模型级 CoT:在训练中嵌入推理链能力,实现原生思考;
- 多模态 CoT:扩展至跨模态逻辑推理,融合语言与感知信息。
这一演化路径标志着大模型从“被提示思考”迈向“自主推理”的阶段性突破。
2.2 CoT推理过程
CoT提示过程,更像是一种提示词工程(Prompt Engineering),通过向大语言模型展示一些少量的 exapmles,在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。
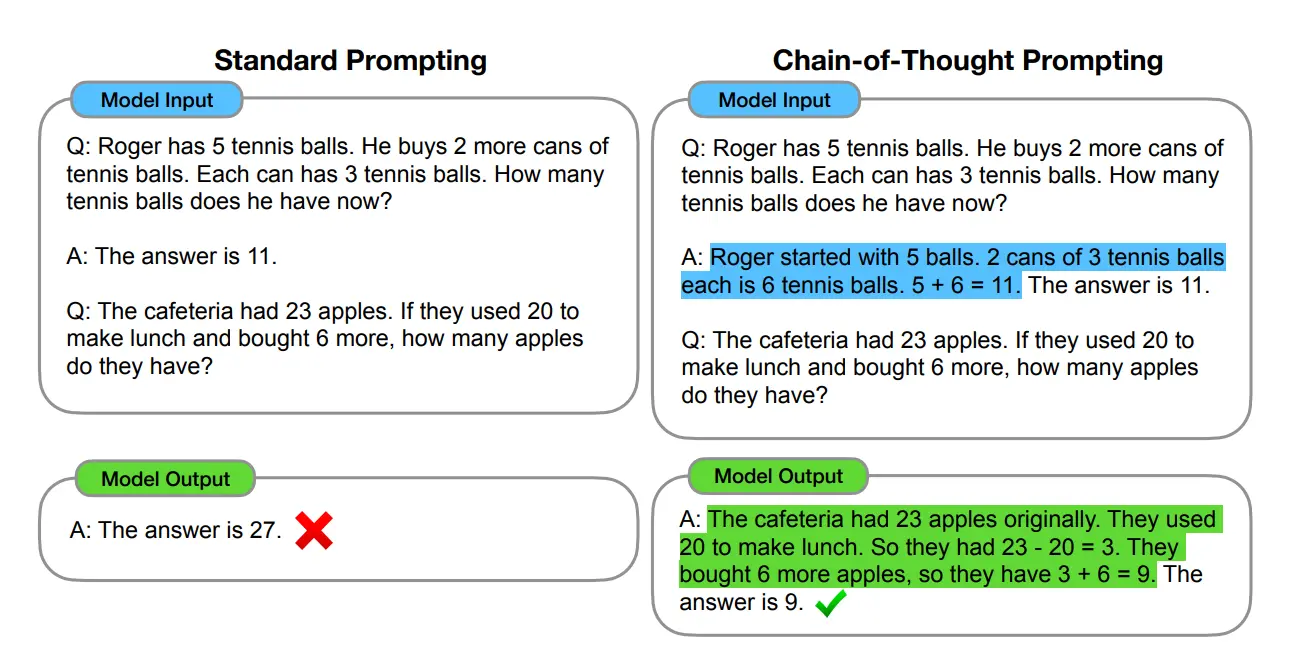
如上图,以一个数学题为例,思维链提示会在给出答案之前,还会自动给出推理步骤,基于示例的方式,得到最终的计算结果
请注意,很多人会把 CoT 和 “详细提示” 搞混,其实两者本质不同:
- 普通提示(比如 “请详细回答”):只要求模型 “把答案说详细”,但没要求 “拆步骤推理”,模型可能还是跳过关键思考环节;
- CoT 提示:强制模型 “拆步骤想”,比如在问题结尾加 “Let’s think step by step”(零样本 CoT),或给几个 “问题 + 推理链 + 答案” 的例子(少样本 CoT),让模型模仿 “分步思考” 的模式。
3. CoT 与 AI Agent
接下来我们再来看一看CoT为什么会成为Agent的主流推理框架之一
3.1 概念层
3.1.1 CoT
上面说到了Chain-of-Thought (CoT) 是一种推理生成机制(reasoning generation mechanism),让模型在回答问题前显式地展开中间推理步骤。
通俗地说,它让模型不直接“给答案”,而是“先想一想再回答”。 它关注的是 “思考的路径”。
3.1.2 Agent
AI Agent(智能体) 是一种具备自主决策、环境交互与长期目标优化能力的系统架构。 它不只是语言模型,而是一个具备以下循环的系统:
感知(Perceive)→ 推理(Reason)→ 决策(Plan)→ 执行(Act)→ 反馈(Reflect)
Agent 的核心特征在于它必须:
- 面对开放环境;
- 基于上下文做多步决策;
- 能调用外部工具或环境接口;
- 能根据反馈进行自我修正。
3.1.3 对比
| 概念 | 关注点 | 核心目标 | 是否可独立存在 |
|---|---|---|---|
| CoT | 模型内部的推理路径 | 提升逻辑一致性与可解释性 | ✅(单模型即可实现) |
| Agent | 系统级决策循环 | 实现自主任务执行 | 🚫(离不开推理机制) |
结论:CoT 是 Agent 的“推理内核”,Agent 是 CoT 的“应用容器”。
3.2 技术逻辑层
AI Agent 想要具备“智能决策”的能力,必须拥有**多步思考(multi-step reasoning)和动态规划(planning)**能力。 而 CoT 正是当前大模型中最有效的“多步思考表示形式”。
3.2.1 CoT 提供了 Agent 的“内在思维空间”(Internal Reasoning Space)
传统语言模型输出的是单步映射:
输入 → 输出
但 Agent 需要一个能在内部进行反思、规划、评估的结构化思维过程。
输入 → (思考链)→ 决策 → 动作 → 环境反馈
在这一结构中,CoT 就是 Agent 的「思维工作记忆(Working Memory)」: 模型通过生成中间推理链,显式地表达自己“在思考什么”, 从而为后续动作提供决策依据。
例如:
任务:安排明天的会议
CoT 推理链:
1. 先确认参与者 → 2. 查看他们的空闲时间 → 3. 查找可用会议室 → 4. 安排会议 → 5. 发送通知
→ 最终决策:明天上午10点,会议室A
在 Agent 框架中,以上 CoT 输出可直接驱动调用外部工具(日程表API、邮件系统)来执行这些步骤。
3.2.2 CoT 是“反思与规划(Reflection & Planning)”机制的基础
在现代 Agent 设计中,存在两种主流推理范式:
| 推理机制 | 核心特征 | 代表实现 |
|---|---|---|
| CoT(Chain-of-Thought) | 线性推理链条,显式展开思考 | GPT-4、DeepSeek-R1 |
| ToT(Tree-of-Thought) | 树状搜索式推理,多路径评估与反思 | Tree-of-Thoughts (Yao et al., 2023) |
| ReAct(Reason + Act) | 推理与行动交替执行 | LangChain / ReAct Agents |
| Reflexion / Self-Refine | 基于 CoT 输出的自我反思与修正 | Reflexion (Shinn et al., 2023) |
注意:这些框架都以 CoT 为基础。
- ReAct 将 CoT 拓展为 “推理链 + 动作链”;
- Tree-of-Thought 则是 CoT 的并行搜索化版本;
- Reflexion 则是在 CoT 基础上增加了 “评估与修正” 模块。
因此,从技术谱系上看:
CoT → ReAct / ToT / Reflexion → Agent Frameworks(如 AutoGPT, LangGraph, Voyager 等)
这也是为什么学术界称 CoT 是 “AI Agent 的推理基石(reasoning substrate)”。
3.2.3 CoT 支撑 Agent 的“显式可解释推理”能力
Agent 需要被监控、调试、解释。 如果模型的决策过程是黑箱式的 end-to-end 输出(没有中间思考过程),就无法解释为何采取某个行动。
而 CoT 提供了一种可追踪的决策链条:
- 每个步骤都可以被解析、验证、修改;
- 可以通过 reward model(奖励模型)对推理链进行强化或惩罚;
- 可以为后续的 meta-agent(监督 agent)提供反思依据。
例如:
CoT 输出:“我认为这家公司明天股价会上涨,因为……”, Agent 上层模块即可分析这条推理链的合理性,并决定是否执行交易动作。
这也是 OpenAI、Anthropic、DeepSeek 在 2024–2025 年各自的 Agent 架构中,都将 “structured reasoning trace” 作为核心模块的原因。
3.3 架构层
下图描述了 CoT 与 Agent 的架构关系(文字版示意):
┌───────────────────────────┐
│ AI Agent │
│ ┌───────────────────────┐ │
│ │ Reasoning Engine │ │ ← 基于 CoT 的推理核心
│ │ (CoT / ReAct / ToT) │ │
│ └───────────────────────┘ │
│ ↑ ↓ │
│ ┌───────────────────────┐ │
│ │ Memory & Context │ │ ← 支撑长期思考与上下文记忆
│ └───────────────────────┘ │
│ ↑ ↓ │
│ ┌───────────────────────┐ │
│ │ Action Executor │ │ ← 调用工具、执行任务
│ └───────────────────────┘ │
└───────────────────────────┘
在这套架构中:
- CoT 是核心推理引擎(Reasoning Engine);
- 它与记忆模块、工具模块交互;
- 输出的思维链结果直接影响行动决策与反馈循环;
- 高级 Agent(如反思型、自演化型 Agent)则在多轮 CoT 之上再叠加元推理(Meta-Reasoning)。
3.4 小结
CoT 作为 Agent 的主流推理框架,其主要原因如下
| 理由 | 解释 |
|---|---|
| 1. CoT 提供了结构化的思维路径 | 使模型从“直接反应”转为“逐步规划” |
| 2. CoT 是多步决策的基础 | Agent 的计划、反思、行动循环都依赖推理链 |
| 3. CoT 支撑可解释与可控性 | 让外部系统理解、修改模型思考过程 |
| 4. CoT 是更复杂推理框架(ReAct、ToT、Reflexion)的母体 | 所有主流 Agent 推理范式都从 CoT 演化而来 |
| 5. 实践验证 | 从 LangChain 到 OpenAI o1-preview,再到 DeepSeek-R1,均以 CoT 风格思维链为决策基石 |
一句话总结
CoT 是 AI Agent 的思维引擎。 它将大模型从“语言生成器”变为“可思考的决策体”, 是连接自然语言理解与自主行动之间的关键逻辑桥梁。
参考资料:
- 大模型Chain-of-Thought(CoT)与Agent基础知识与介绍_cot 大模型-CSDN博客
- 一文读懂:思维链 CoT(Chain of Thought)
- 大模型思维链(Chain-of-Thought)技术原理 - 知乎
- Igniting Language Intelligence: The Hitchhiker’s Guide From Chain-of-Thought Reasoning to Language Agents
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- 大模型:豆包 + ChatGpt