01.AI Agent Google白皮书
以下内容来自于大模型对 Agents谷歌白皮书 的翻译内容提取
1.序
人类非常擅长识别复杂的模式。他们是怎么做到的呢?
-- 借助于外部外部工具,如书籍、网络搜索或者计算器之类的工具,来补充一有的知识,然后再得出结论
对于生成式人工智能模型,同样也可以通过训练来使用工具,以此来访问实时信息或者给出行动建议,如
- 利用数据库查询工具获取客户的购物历史,然后给出购物意见
- 根据用户的查询,调用相应的API,替用户回复电子邮件或者完成金融交易
大模型要实现这个,则要求模型不仅需要访问外部工具,还要能够自主规划和执行任务。 这种具备了推理、逻辑和访问外部信息的生成式 AI 模型,就是 Agent 的概念;
换句话说,Agent 是一个扩展了生成式AI模型出厂能力的程序。
2.什么是Agent
2.1 基本概念
简单说,Agent 是 “带脑子 + 带手脚 + 会规划” 的生成式 AI 应用 —— 它能自己定目标、用工具、调资源,不用人一步步指挥,就能完成任务。
- Agent拥有自主能力(autonnomous): 只要提供了合适的目标,它们就能独立行动,无需人类干预
- 即使是模糊的人类指令,Agent也可以推理出它接下来应该做什么,并采取行动,最终实现其目标
2.2 认知架构(congnitive architecture)
驱动Agent的行为、动作、决策(behavior, actions, decision marking)共同组合成Agent的认知架构
在这个架构中,有三个核心组件,如下面的认知架构图
- model: 模型
- tool: 工具
- orchestration: 编排层
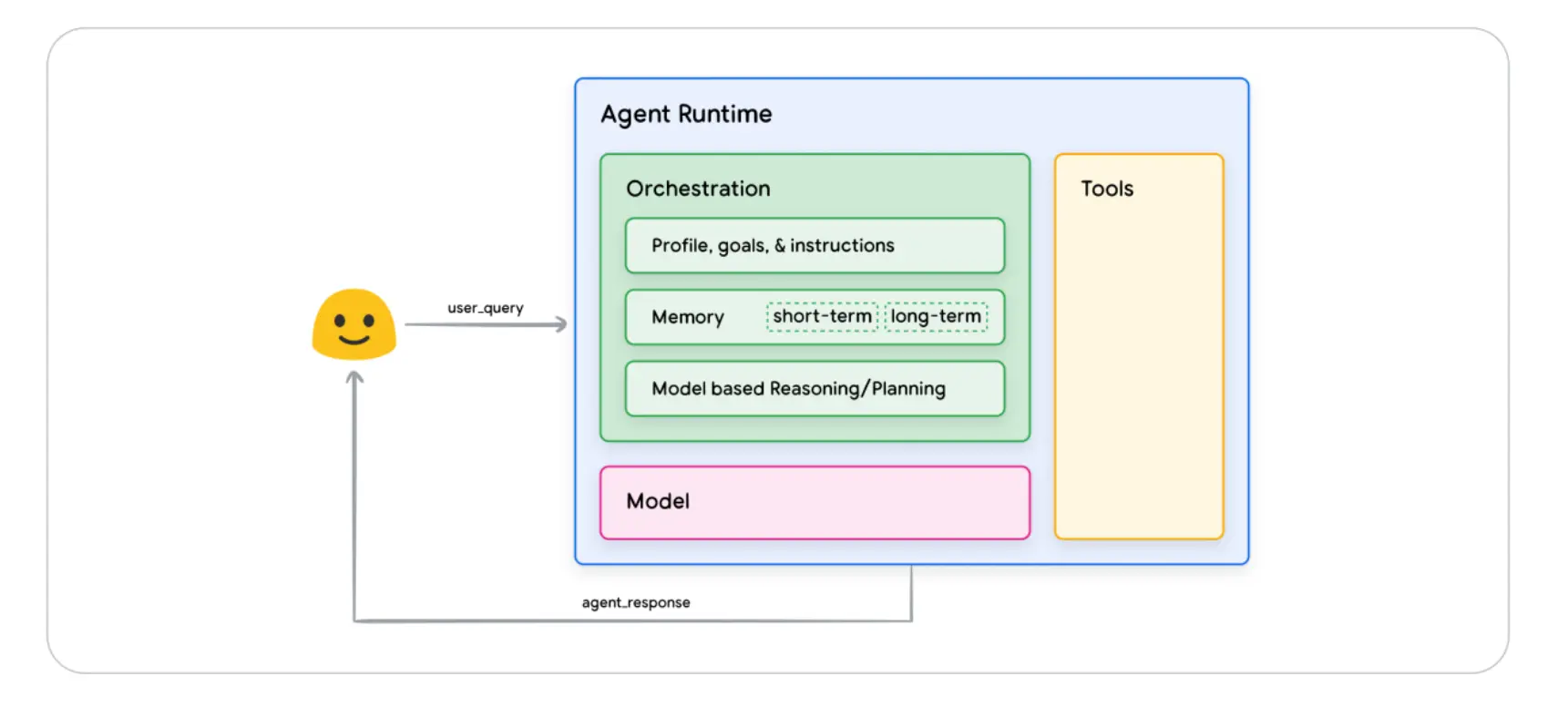
2.2.1 模型 model
在Agent领域中,model通常指的是用于做核心决策的语言模型(LM)
- 可以是大模型,也可以是小模型(LLM/SLM)
- 需要遵循基于指令的推理和逻辑框架(ReAct, Chain-of-Thought, Tree-of-Thought)
- 可以是通用、多模态的模型,或者根据特定的Agent架构的需求微调的模型
- 为了获得更好的执行效果,推荐根据已有的工具、数据集、编排推理设置,对模型进行训练/微调,以此来获得更稳定表现的模型
2.2.2 工具 tool
基础模型在文本和图像生成方面非常抢单,但是无法预外部世界联动,则极大的限制了它们的能力。工具(tool)则可以解决这个问题,Agent通过工具与外部数据和服务互动,从而扩展模型的能力边界
工具可以有多种表现形式,最常见的是通过WEB API(如GET/POST/PATCH/DELETE等http调用) 方式提供的工具能力
2.2.3 编排层 ochestration
编排层主要描述了一个循环过程,用于控制Agent如何接收消息、执行内部推理、并使用推来结果来指导下一步的行动或者决策
对于编排层,有两个显著的特点:
- 通常来说,这个循环过程会持续进行,直到Agent达到其目标或触发停止条件
- 编排层的复杂性和Agent及其执行的任务直接相关,差异可能很大
2.2.4 Agent vs Model
代表对比了Agent与模型之间的区别
| 对比 | 模型 | Agent |
|---|---|---|
| 知识范围 | 知识仅限于其训练数据。 | 通过工具连接外部系统,能够在模型自带的知识之外,实时、动态扩展知识。 |
| 状态与记忆 | 无状态,每次推理都跟上一次没关系,除非在外部给模型加上会话历史或上下文管理能力。 | 有状态,自动管理会话历史,根据编排自主决策进行多轮推理。 |
| 原生工具 | 无。 | 有,自带工具和对工具的支持能力。 |
| 原生逻辑层 | 无。需要借助提示词工程或使用推理框架(CoT、ReAct 等)来形成复杂提示,指导模型进行预测。 | 有,原生认知架构,内置 CoT、ReAct 等推理框架或 LangChain 等编排框架。 |
3.认知架构:Agent如何工作
3.1 以厨师为例,类比Agent的工作流程
厨师的职责是根据顾客的菜单,烹饪对应的菜品。 这个操作流程类似上面说到的规划——执行——调整(planning - execution - adjustment)循环过程
- 收集信息(输入):顾客点的菜单,后厨现有的食材等
- 推理(思考): 根据收集的信息,判断可以做哪些采
- 做菜(执行): 切菜、烹饪、出锅
在上面的每个阶段过程,厨师都需要根据实际情况进行调整,比如突然某个食材不够了,需要找顾客协商换一道菜;根据顾客的饮食偏好,添加不同的调料(如有人要清淡、有人要重口),通过这些调整,不断的完善整个做菜过程
这个信息接收、规划、执行和调整(information intake, planning, executing, and adjusting)的循环描述的就是一个厨师用来实现其目标的特定认知架构。
3.2 Agent 推理框架
Agent的核心是编排层,负责维护记忆、状态、推理和规划(memory, state, reasoning and planning)
使用快速发展的提示词工程(prompt engineering)及相关框架来指导推理和规划,使Agent能更有效的与环境互动来完成任务
白皮书中提到了三种推理框架和推理计数
- ReAct: 为LM提供了一个思考过程的策略
- Cot(Chain-of-Thought):思维链,通过中间步骤实现推理能力 (有各种子技术,如自我一致性、主动提示、多模态CoT)
- ToT(Tree-of-Thoughts):思维树,适合探索或战略前瞻任务。概括了链式思考提示,并允许模型探索各种思考链,作为使用语言模型解决问题的中间步骤。
3.3 ReAct示例
Agent 可以使用以上一种或多种推理技术,给特定的用户请求确定下一个最佳行动。 例如,使用 ReAct 的例子
- 用户向 Agent 发送查询。
- Agent 开始 ReAct sequence。
- Agent 提示模型,要求其生成下一个 ReAct 步骤及其相应的输出:
- 问题:提示词 + 用户输入的问题
- 思考:模型的想法:下一步应该做什么
- 行动:模型的决策:下一步要采取什么行动。这里就是可以引入工具的地方, 例如,行动可以是
[Flights, Search, Code, None]中的一个,前三个代表模型可以选择的已知工具,最后一个代表“无工具选择”。 - 行动的输入:模型决定是否要向工具提供输入,如果要提供,还要确定提供哪些输入
- 观察:行动/行动输入序列的结果。根据需要,这个思考/行动/行动输入/观察
(thought / action / action input / observation)可能会重复 N 次。 - 最终答案:模型返回对原始用户查询的最终答案。
- ReAct 循环结束,并将最终答案返回给用户。
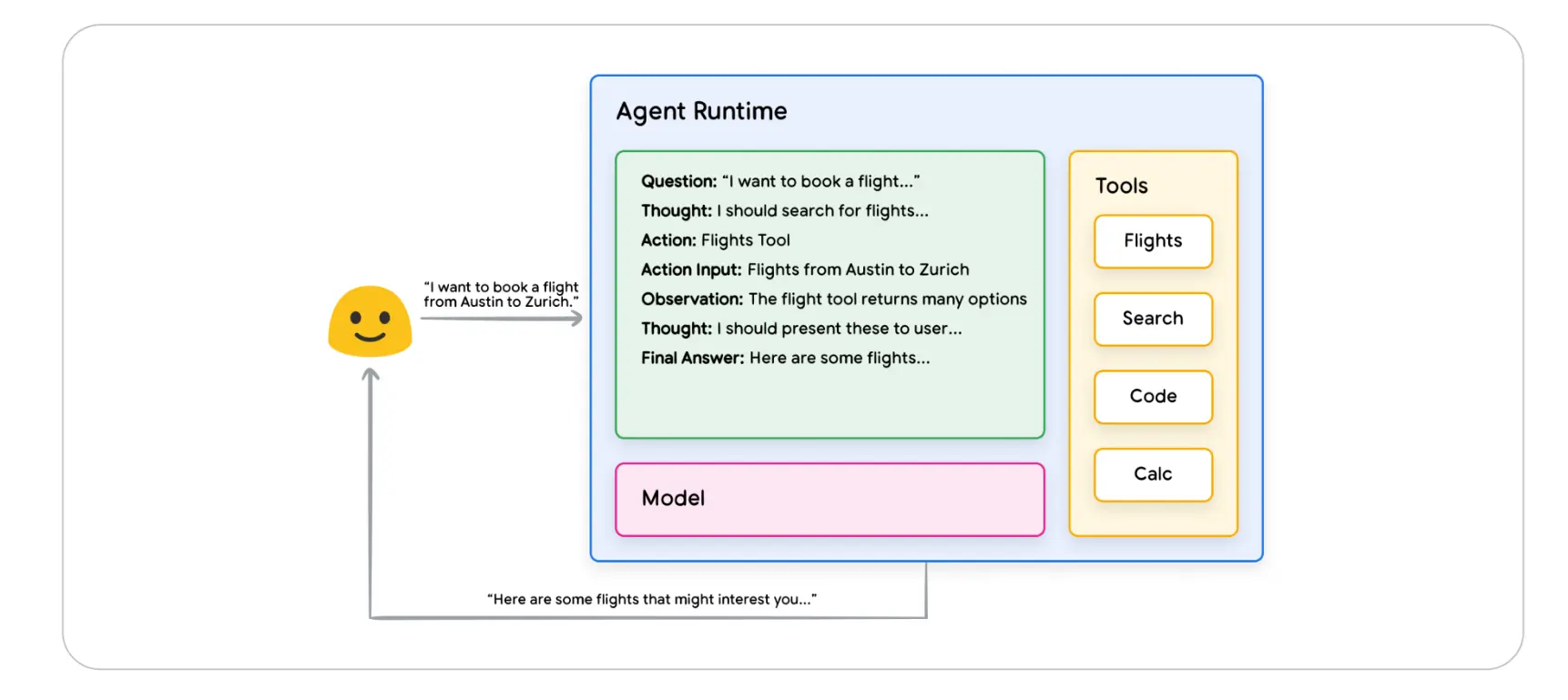
如上图,模型、工具和Agent配置共同工作,根据用户的输入,返回一个有根据的、简洁的响应。虽然模型第一轮根据其先前知识猜了一个答案(幻觉),但它接下来使用了一个工具(航班)来搜索实时外部信息,从而能根据真实数据做出更明智的决策,并将这些信息总结回给用户。
Agent 的响应质量与模型的推理能力和执行任务的能力直接相关,包括选择正确工具的能力,以及工具自身的定义的好坏(how well that tools has been defined)。就像厨师精选食材、精心做菜,并关注顾客的反馈一样,Agent 依赖于合理的推理和可靠的信息来提供最佳结果。
4.工具:模型链接真实世界的关键
语言模型很擅长处理信息,但它们缺乏直接感知和影响现实世界的能力。在需要与外部系统或数据联动的情况下,这些模型的实用性就很低了。 某种意义上说,语言模型的能力受限于它们的训练数据中覆盖到的信息
为了赋予模型与外部系统进行实时、上下文感知的互动能力,通常有下面几种方式(统称为工具 Tools)
- Functions
- Extensions
- Data Stores
- Plugins
4.1 Extensions
extension 是一种以标准化方式连接 API 与 Agent 的组件, 使 Agent 能够调用外部 API,而不用管这些 API 背后是怎么实现的。
假设你想创建一个帮用户预定航班的Agent,并使用Google Flights API来搜索航班信息,但不确定如何让你的Agent调用这个API

4.1.1 传统方式
写代码,从用户输入中解析城市等相关信息,然后调用API,如
- 用户输入 “I want to book a flight from Austin to Zurich”(“我想从奥斯汀飞往苏黎世”); 我们的代码需要从中提取“Austin”和“Zurich”作为相关信息,然后才能进行 API 调用。
- 但如果用户输入“I want to book a flight to Zurich”,我们就无法获得出发城市信息,进而无法成功调用 API,所以需要写很多代码来处理边界 case。
显然,这种方法维护性和扩展性都很差。有没有更好的解决方式呢? 这就轮到 exntension 出场了。
4.1.2 使用Extension
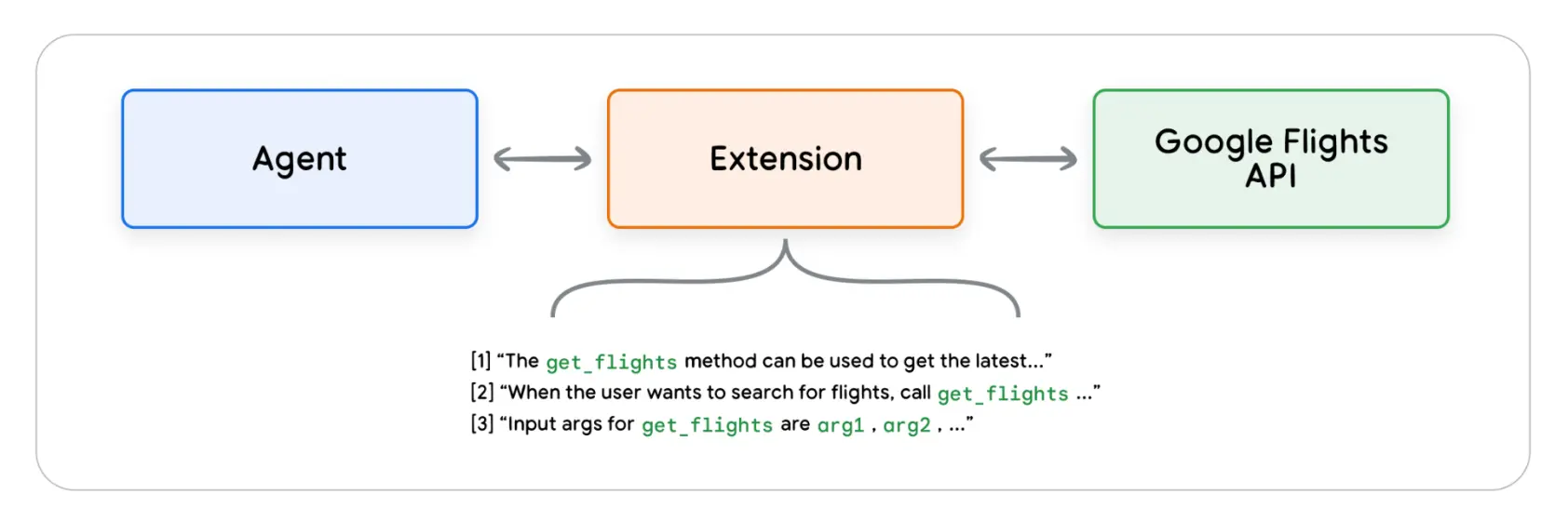
如图,Extension通过以下方式将Agent与API串起来
- 提供示例信息告诉Agent如何使用API
- 告诉Agent调用API所需的具体参数
Extension 可以独立于 Agent 开发,但应作为 Agent 配置的一部分。 Agent 在运行时,根据提供的示例和模型来决定使用哪个 extension 来处理用户的查询, 这突出了 extension 的一个核心优势:built-in example types, 允许 Agent 动态选择最适合所执行任务的 extension,如下图所示

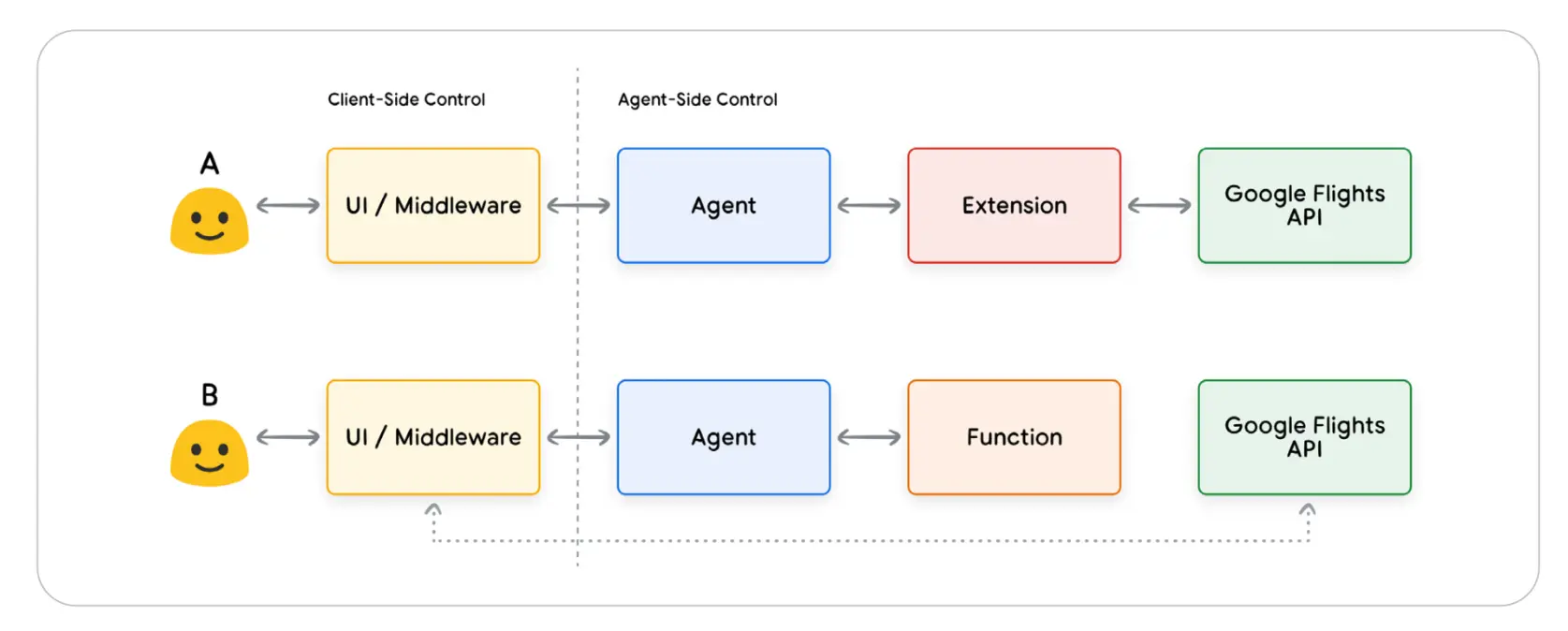
4.2 Functions
在程序员的日常工作中,“函数”指的是自包含的代码模块,用于完成特定任务,并可以复用(被不同地方的代码调用)
在Agent的世界中,函数的工作方式非常相似——知识将软件开发者替换为模型。模型可以设置一组已知的函数,然后就可以根据规范决定何时使用哪个函数,以及函数需要哪些参数
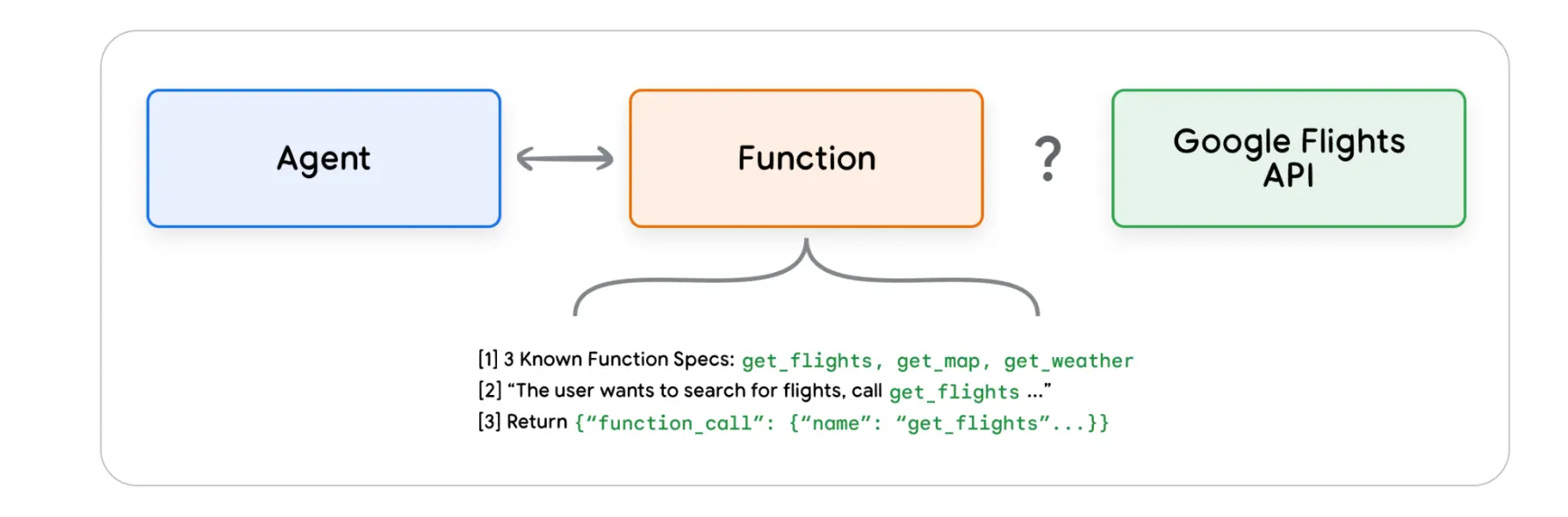
- 模型只输出函数名及参数信息,不会执行函数调用
- 函数在客户端执行,作为对比的是Extension在Agent端执行
4.2.1 Functions vs Extention
对于Function,与Extention的核心区别在于,调用实际API的逻辑和执行将从代理返回给用户,因此开发人员可以对应用程序中的数据流进行更精细的控制,常见于
- 并不希望直接调用API,而是由应用程序的其他层来调用
- 因为安全身份校验,不支持Agent直接访问的场景
- 不希望实时调用的场景(如需要人工review执行链路)
4.2.2 示例
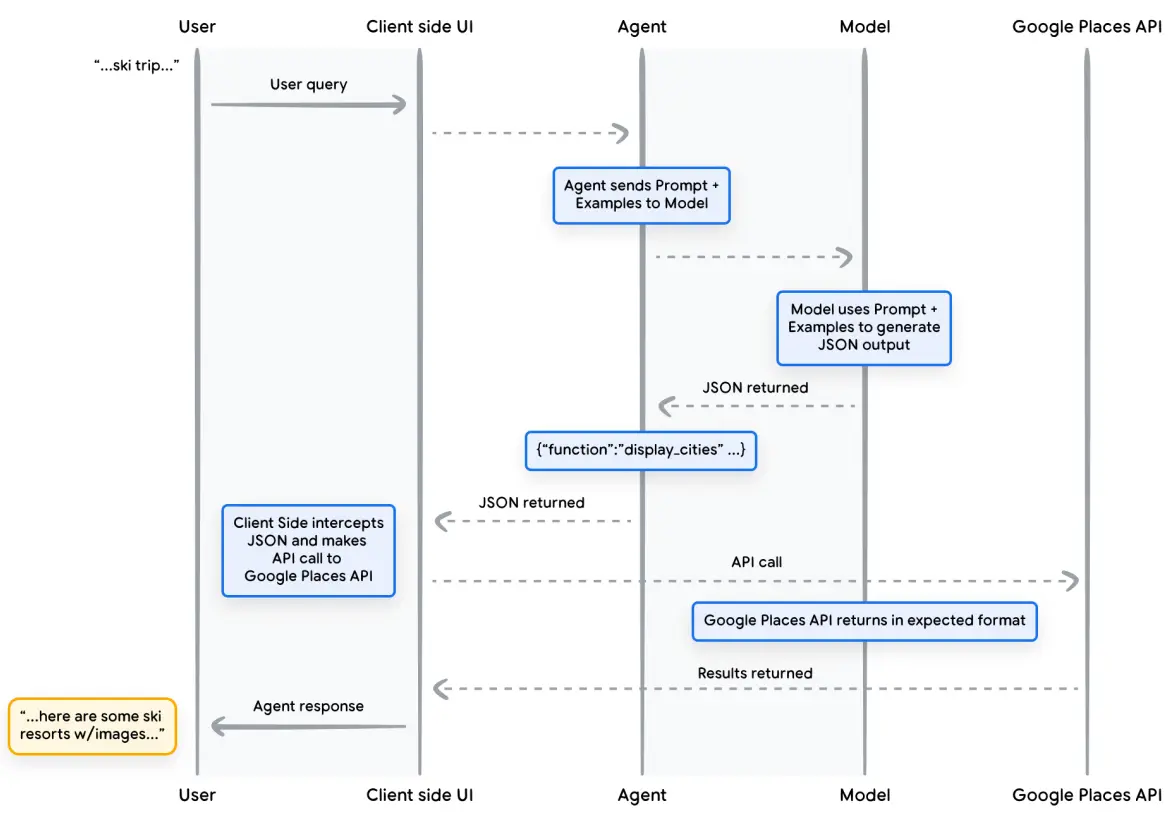
考虑以下例子,实现一个 AI Traval Agent,它会与想要旅行的用户互动。 我们的目标是让 Agent 生成一个城市列表,然后就可以下载相应城市的图片、数据等,以供用户旅行规划使用。
用户输入:
I’d like to take a ski trip with my family but I’m not sure where to go.
模型输出可能如下
Sure, here’s a list of cities that you can consider for family ski trips:
- Crested Butte, Colorado, USA
- Whistler, BC, Canada
- Zermatt, Switzerland
虽然以上输出包含了我们需要的数据(城市名称),但格式不适合解析。 通过 Function,我们可以教模型以结构化风格(如 JSON)输出,以便其他系统解析。
{
"name": "display_cities",
"args": {
"cities": ["Crested Butte", "Whistler", "Zermatt"],
"preferences": "skiing"
}
}
这个Agent应用的整体流程图如下
4.3 data storage
语言模型就像一个大图书馆,其中包含了其训练数据(信息)。但与真实世界的图书馆不同的是,这个图书馆是静态的 —— 不会更新,只包含其最初训练时的知识。而现实世界的知识是不断在演变的,所以静态模型在解决现实世界问题时就遇到了挑战。
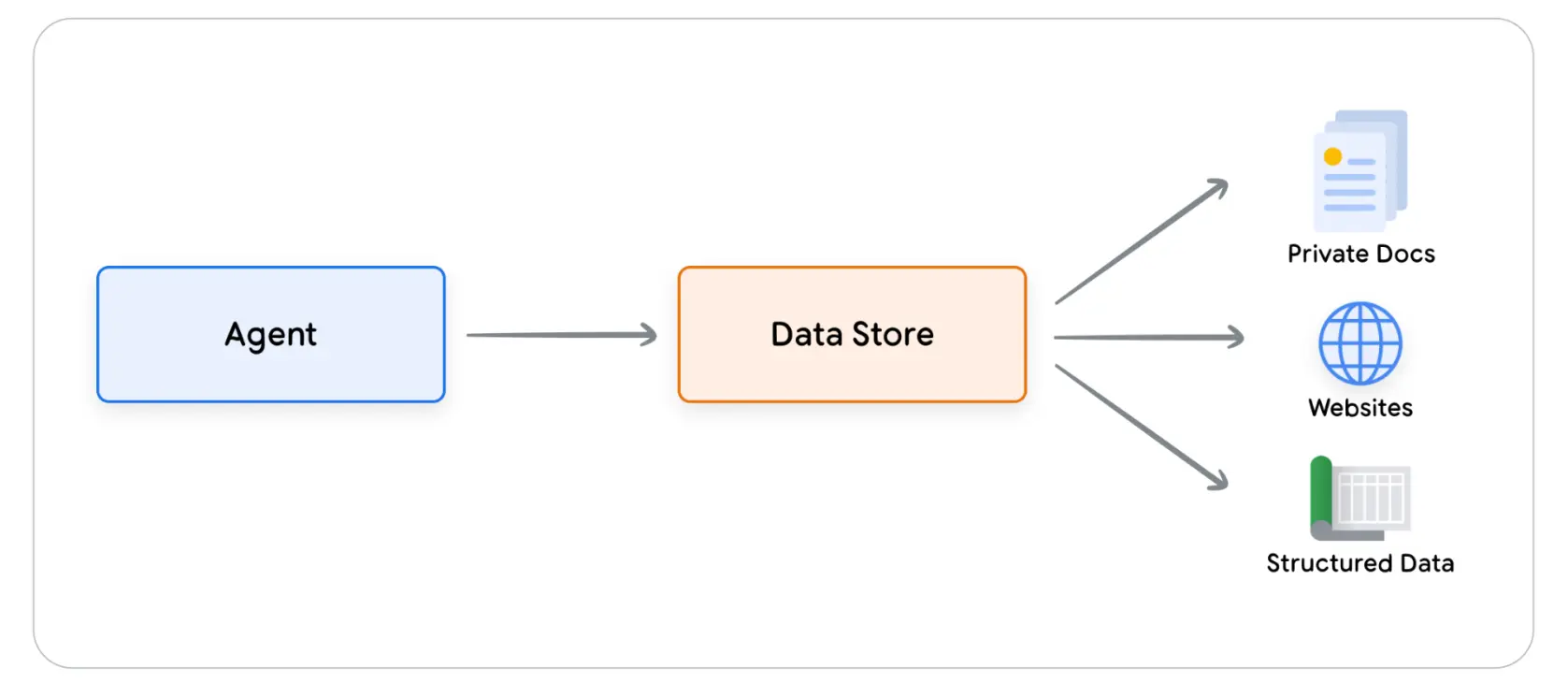
Data Storage 通过提供动态更新的信息来解决这一问题,
- 允许开发人员以原始格式向
Agent提供增量数据,将传入的文档转换为一组向量数据库嵌入,Agent可以使用这些embedding来提取信息。 - 增量数据补充,无需耗时的数据转换、模型重新训练、微调
4.3.1 实现与应用
在生成式 AI 场景,Agent 使用的数据库一般是向量数据库 —— 它们以向量 embedding 的形式存储数据,这是一种高维向量或数学表示。
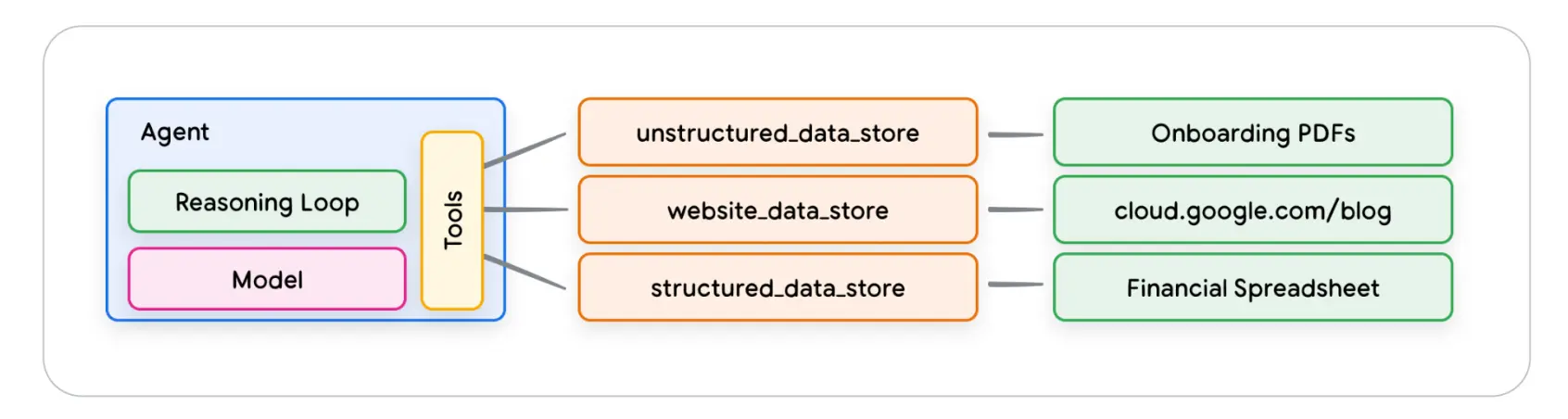
使用语言模型与 Data Storage 的最典型例子是检索增强生成(RAG - Retrieval Augmented Generation),RAG 应用程序通过让模型访问各种格式的数据来扩展模型知识的广度和深度,如:
- 网站内容
- 结构化数据,如pdf/word/csv/电子表格等
- 非结构化数据,如HTML/PDF/TXT等
用户请求和Agent响应循环的基本过程如下图
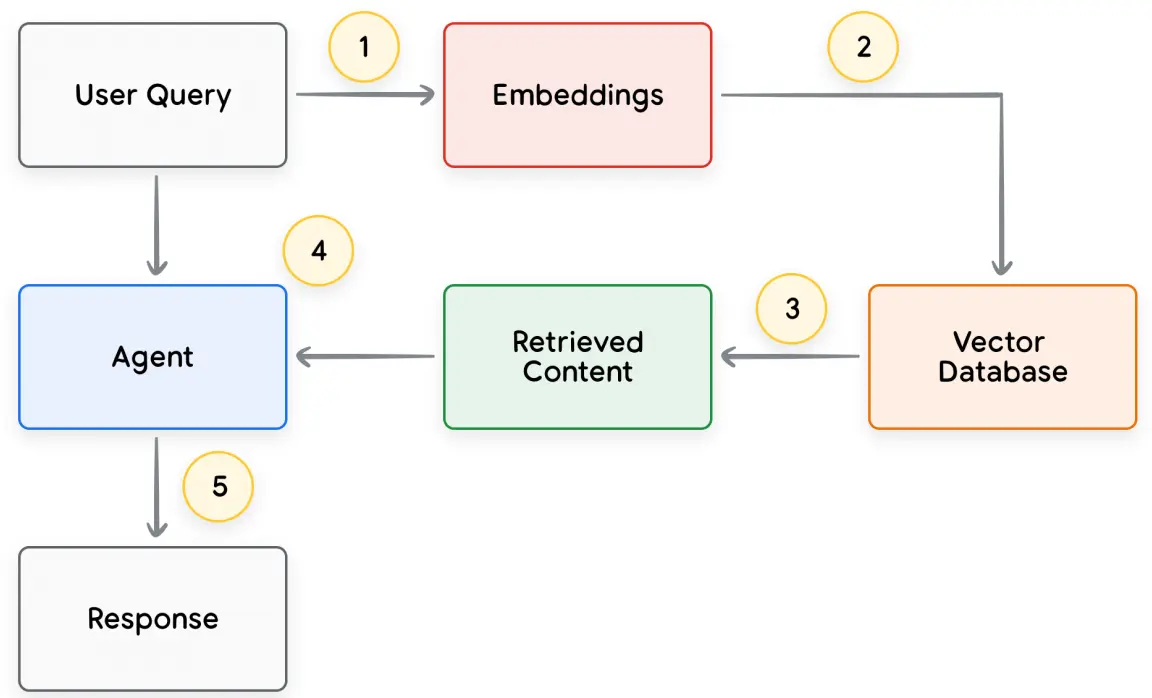
- 用户请求 发送到嵌入模型(embedding model),生成嵌入查询(query embedding)。
- 将嵌入查询与向量数据库的内容进行匹配,本质上就是在计算相似度。
- 将相似度最高的内容以文本格式发送回
Agent。 Agent决定响应或行动。- 最终响应发送给用户。
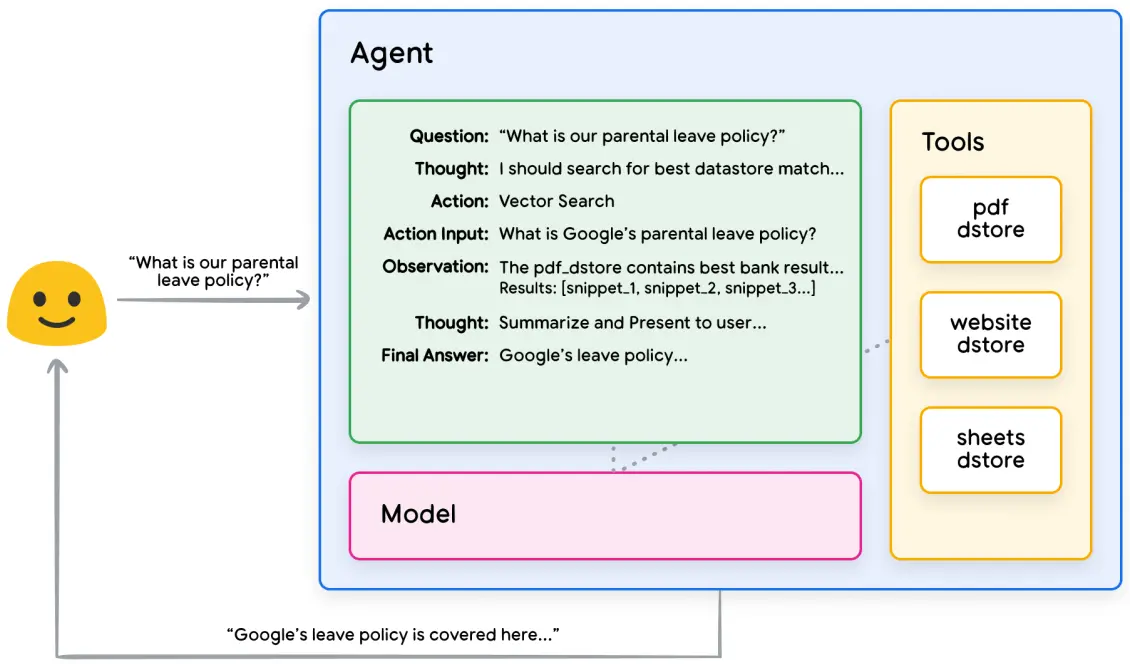
4.3.2 示例
一个RAG与ReAct推理/规划的Agent示例
4.4 小结
总结来说,Extension、Function 和 Data Storage 是 Agent 在运行时可以使用的几种不同工具类型。 每种工具都有其特定的用途,可以根据 Agent 开发人员的判断单独或一起使用。
| 对比 | Extensions | Function Calling | Data Stores |
|---|---|---|---|
| Execution 执行 | Agent执行 | Client执行 | Agent执行 |
| 使用场景 | - 开发人员希望 Agent 控制 API 的调用 - 使用 native pre-built Extensions (i.e., Vertex Search, Code Interpreter, etc.) 时比较有用 - Multi-hop planning and API calling (i.e., 下一个 action 取决于前一个 action/API call 的输出) | - 安全或认证等原因,导致 Agent 无法直接调用 API 的场景 - 时序或者操作顺序限制,导致 Agent 无法直接事实调用 API 的场景,(i.e., batch operations, human-in-the-loop review, etc.) - API 没有暴露给公网,只能在内部使用的场景。 | RAG |
5.通过针对性学习提升模型性能
有效使用模型的一个关键是,让模型具备在生成输出时选择正确工具的能力。虽然一般训练有助于模型获得这种技能,但现实世界的场景通常需要超出训练数据的知识。 这就像是掌握基本做菜技能和精通特定菜系之间的区别,两者都需要基础烹饪知识,但后者需要针对性学习以获得更好的垂类结果。
通常有下面几种方法
5.1 In-Context learnging:基于上下文学习
使用通用模型,但在推理时为模型提供提示词、工具和示例,使模型其能够“即时学习”如何以及何时为特定任务使用这些工具。 如ReAct框架
5.2 Retrieval-based in-context learnging: 基于检索的上下文学习
通过从外部存储中检索相关信息、工具和示例来动态填充模型提示词,如RAG
5.3 Fine-utning based learning: 基于微调的学习
用大量的特定示例对模型进行训练(微调/精调),然后用微调过的模型进行推理。
这有助于模型在接收到任何用户查询之前,理解何时以及如何应用某些工具。
6.总结
本文讨论了生成式 AI Agent 的基础构建模块及工作原理。一些关键信息:
- Agent 的核心价值:让生成式 AI 从 “生成内容” 升级为 “完成任务”,能自主规划、用工具、对接真实世界
- 三大关键:模型(思考)、工具(行动)、编排层(流程)
- 工具选对很重要:直接用 Extension,安全可控用 Function,需要实时 / 私有数据用 Data Store
- 推理框架:ReAct, CoT, ToT, (以及本文未提到的Plan-and-Execute)
- 未来方向:多个 Agent 分工合作(比如一个负责旅行规划,一个负责订机票,一个负责订酒店),解决更复杂的问题
最后需要说明,复杂的 Agent 架构并不是一蹴而就的,需要持续迭代(iterative approach)。 给定业务场景和需求之后,不断的实验和改进是找到解决方案的关键。