1. 诞生的契机
为什么会萌发写一个记录链路耗时的组件的念头呢? 来源于一个不太美妙的线上问题。 自从开始做toB的业务之后,对系统的性能要求阈值不断下降,当一个接口响应超过3s时,发现适应适应还可接受,然后逐渐的,你会发现接口的响应会滑向5s、10s... (底线一段突破,那就将没有底线可言)
在经历某一次重大的迭代之后,整体的数据量翻了两翻,部分接口的响应直接突破10s,然后业主方终于是不能忍了,明确提出要求做性能优化
那么怎么做呢?
按照一般的做事惯例,先定目标,然后基于现状拆解任务,接着就是任务的研发推进,最终的交付测试上线
当明确提出要优化某个接口时,至少我们现在的目标是明确,要缩减接口的耗时
现在也是明确的,接口响应很慢。 那么我们的任务也相对明确,即是解决接口响应慢的问题。 接下来就自然有一个疑问,到底是哪里慢了? 对应的策略有两种
- 老老实实啃代码,根据个人经验来判断慢的点
- 借助一些工具,输出各关键节点的耗时分布情况,直观上找到性能瓶颈点
对于第一点,没有什么好说的;重点看一下第二个,我现在迫切需要一个工具,能帮我分析整个接口的执行链路中,是哪些环节会比较慢
现在我有什么?
- skywalking
- loki + grafana
既然有全链路监控神器Skywalking,当然想着就是充分利用起来,先直接观察一下链路的执行情况
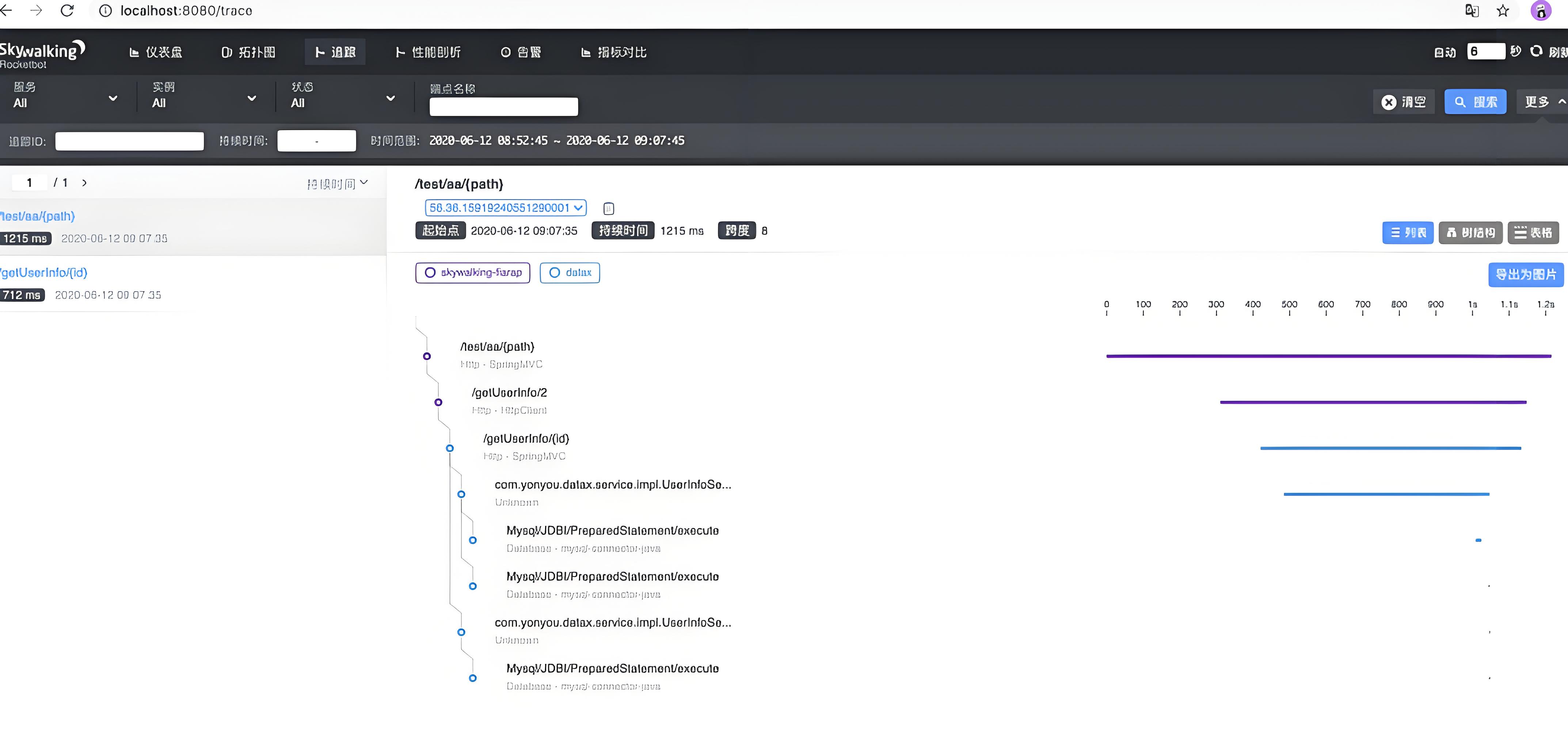
默认的Skywalking的链路追踪中,主要显示的是一些io相关的耗时操作,对于我们实际的业务场景有帮助,但不大(链路长、网络io非常多,很难精确定位到具体是哪里耗时久)
此时就需要我们主动在代码的方法上埋点,通过@Trace注解来手动插入LocalSpan,从而增加关键方法的执行情况输出;接下来我遇到另外一个稍显现实的问题,特么的代码写得有点拉跨,大部分逻辑放在一个方法里,咋搞....
关于skywalking的基础知识点:(Skywalking的埋点-Trace的基本概念 - 简书)
接下来只能老老实实的在代码中通过 StopWatch 来统计代码块的执行耗时情况了,耗时打印输出日志,借助loki+grafana来统一收集查看,也能满足诉求,但是,这种方式写出来的代码,会导致本就岌岌可危的业务代码,又添加了一堆无甚鸟用的逻辑,实在是有点难以忍受; 还有另外一个严重的问题,则是StopWatch对并发的支持不行,对于链路中存在异步调用的场景下,会出现统计偏差或异常
既然现存的工具栈不合心意,那就自己搞一个,先指定几个基本要求:
- 不会引入新的问题
- 使用简单方便,输出直观的耗时统计
- 对现有的业务代码块侵入较小
- 支持链路中存在并行任务执行场景的耗时统计
- 可以方便的将某些方法/代码块,由同步的调度改成异步的调度,从而提高接口性能
接下来我们将正式进入实现篇,如何从0到1手撸一个耗时分布统计的工具组件