2.文档新增与修改使用姿势
大多涉及到数据的处理,无非CURD四种操作,对于搜索SOLR而言,基本操作也可以说就这么几种,在实际应用中,搜索条件的多样性才是重点,我们在进入复杂的搜索之前,先来看一下如何新增和修改文档
I. 环境准备
solr的基础环境需要准备好,如果对这一块有疑问的童鞋,可以参考下上一篇博文: 《190510-SpringBoot高级篇搜索之Solr环境搭建与简单测试》
1. 环境配置
在pom文件中,设置好对应的依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.4.RELEASE</version>
<relativePath/> <!-- lookup parent from update -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-cloud.version>Finchley.RELEASE</spring-cloud.version>
<java.version>1.8</java.version>
</properties>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</pluginManagement>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-solr</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
因为我们采用默认的solr访问姿势,所以配置文件中可以不加对应的参数,当然也可以加上
打开 application.yml 配置文件
spring:
data:
solr:
host: http://127.0.0.1:8983/solr
如果我们的solr加上了用户名密码访问条件,参数中并没有地方设置username和password,那应该怎么办?
spring:
data:
solr:
host: http://admin:admin@127.0.0.1:8983/solr
如上写法,将用户名和密码写入http的连接中
2. 自动装配
我们主要使用SolrTemplate来和Solr打交到,因此我们需要先注册这个bean,可以怎么办?
package com.git.hui.boot.solr.config;
import org.apache.solr.client.solrj.SolrClient;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.solr.core.SolrTemplate;
/**
* Created by @author yihui in 19:49 19/5/10.
*/
@Configuration
public class SearchAutoConfig {
@Bean
@ConditionalOnMissingBean(SolrTemplate.class)
public SolrTemplate solrTemplate(SolrClient solrClient) {
return new SolrTemplate(solrClient);
}
}
上面的配置是条件注入,只有当SolrTemplate对应的bean没有被自动加载时,才会加载,为什么要怎么干?
(可以想一想原因...)
II. 使用姿势示例
我们的操作主要依赖的是SolrTemplate,因此有必要在开始之前,看一下它的签名
Spring的源码中,可以发现大多xxxTemplate都会实现一个xxxOperations 接口,而这个接口就是用来定义CURD的api,比如我们看下 SolrOperations中与修改相关的api
default UpdateResponse saveBean(String collection, Object obj) {
return saveBean(collection, obj, Duration.ZERO);
}
/**
* Execute add operation against solr, which will do either insert or update with support for commitWithin strategy.
*
* @param collection must not be {@literal null}.
* @param obj must not be {@literal null}.
* @param commitWithin max time within server performs commit.
* @return {@link UpdateResponse} containing update result.
*/
UpdateResponse saveBean(String collection, Object obj, Duration commitWithin);
default UpdateResponse saveBeans(String collection, Collection<?> beans) {
return saveBeans(collection, beans, Duration.ZERO);
}
UpdateResponse saveBeans(String collection, Collection<?> beans, Duration commitWithin);
default UpdateResponse saveDocument(String collection, SolrInputDocument document) {
return saveDocument(collection, document, Duration.ZERO);
}
/**
* Add a solrj input document to solr, which will do either insert or update with support for commitWithin strategy
*
* @param document must not be {@literal null}.
* @param commitWithin must not be {@literal null}.
* @return {@link UpdateResponse} containing update result.
* @since 3.0
*/
UpdateResponse saveDocument(String collection, SolrInputDocument document, Duration commitWithin);
default UpdateResponse saveDocuments(String collection, Collection<SolrInputDocument> documents) {
return saveDocuments(collection, documents, Duration.ZERO);
}
UpdateResponse saveDocuments(String collection, Collection<SolrInputDocument> documents, Duration commitWithin);
上面的api签名中,比较明确的说明了这个 saveXXX 既可以用来新增文档,也可以用来修改文档,主要有提供了两类
- 单个与批量
- saveDocument 与 saveBean
1. 添加文档
从上面的api签名上看,saveDocument 应该是相对原始的操作方式了,因此我们先看下它的使用姿势
a. saveDocument
首先就是创建文档 SolrInputDocument 对象,通过调用addField来设置成员值
public void testAddByDoc() {
SolrInputDocument document = new SolrInputDocument();
document.addField("id", 3);
document.addField("title", "testAddByDoc!");
document.addField("content", "通过solrTemplate新增文档");
document.addField("type", 2);
document.addField("create_at", System.currentTimeMillis() / 1000);
document.addField("publish_at", System.currentTimeMillis() / 1000);
UpdateResponse response = solrTemplate.saveDocument("yhh", document);
solrTemplate.commit("yhh");
System.out.println("over:" + response);
}
b. saveBean
前面需要创建SolrInputDocument对象,我们更希望的使用case是直接传入一个POJO,然后自动与solr的filed进行关联
因此一种使用方式可以如下
- 定义pojo,成员上通过 @Field 注解来关联solr的field
- pojo对象直接当做参数传入,保存之后,执行 commit 提交
@Data
public static class DocDO {
@Field("id")
private Integer id;
@Field("title")
private String title;
@Field("content")
private String content;
@Field("type")
private Integer type;
@Field("create_at")
private Long createAt;
@Field("publish_at")
private Long publishAt;
}
/**
* 新增
*/
private void testAddByBean() {
DocDO docDO = new DocDO();
docDO.setId(4);
docDO.setTitle("addByBean");
docDO.setContent("新增一个测试文档");
docDO.setType(1);
docDO.setCreateAt(System.currentTimeMillis() / 1000);
docDO.setPublishAt(System.currentTimeMillis() / 1000);
UpdateResponse response = solrTemplate.saveBean("yhh", docDO);
solrTemplate.commit("yhh");
System.out.println(response);
}
c. 批量
批量的方式就比较简单了,传入集合即可
private void testBatchAddByBean() {
DocDO docDO = new DocDO();
docDO.setId(5);
docDO.setTitle("addBatchByBean - 1");
docDO.setContent("新增一个测试文档");
docDO.setType(1);
docDO.setCreateAt(System.currentTimeMillis() / 1000);
docDO.setPublishAt(System.currentTimeMillis() / 1000);
DocDO docDO2 = new DocDO();
docDO2.setId(6);
docDO2.setTitle("addBatchByBean - 2");
docDO2.setContent("新增一个测试文档");
docDO2.setType(1);
docDO2.setCreateAt(System.currentTimeMillis() / 1000);
docDO2.setPublishAt(System.currentTimeMillis() / 1000);
UpdateResponse response = solrTemplate.saveBeans("yhh", Arrays.asList(docDO, docDO2));
solrTemplate.commit("yhh");
System.out.println(response);
}
d. 测试
上面的几个方法,我们执行之后,我们看下是否能查询到新增加的数据
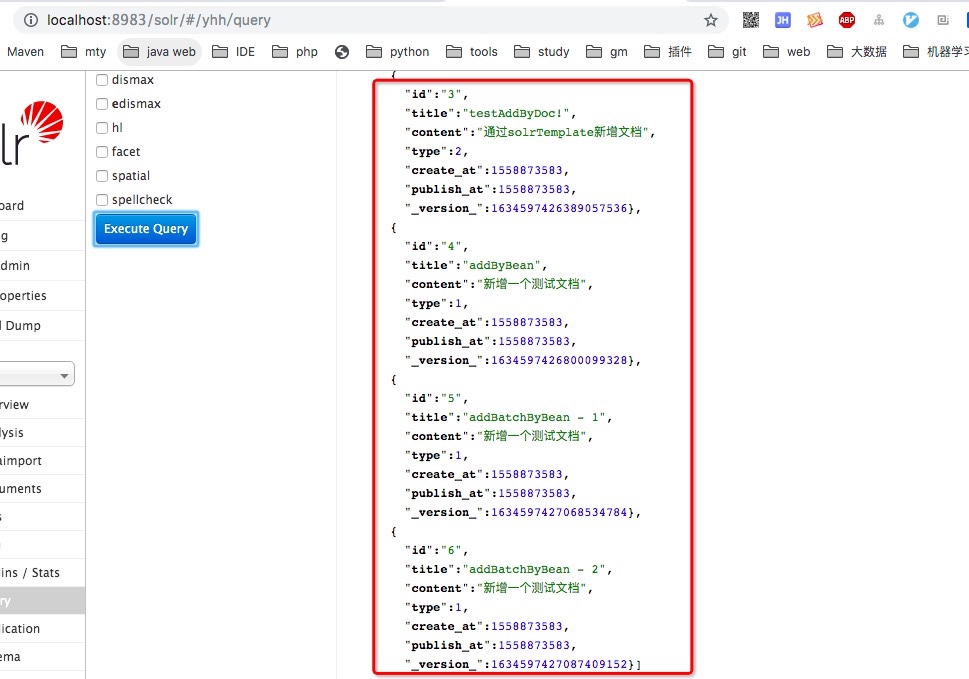
2. 文档修改
在看前面的接口签名时,就知道修改和新增用的是相同的api,所以修改文档和上面的使用实际上也没有什么特别的,下面简单的演示一下
public void testUpdateDoc() {
DocDO docDO = new DocDO();
docDO.setId(5);
docDO.setTitle("修改之后!!!");
docDO.setType(1);
docDO.setCreateAt(System.currentTimeMillis() / 1000);
docDO.setPublishAt(System.currentTimeMillis() / 1000);
UpdateResponse response = solrTemplate.saveBean("yhh", docDO);
solrTemplate.commit("yhh");
System.out.println(response);
}
上面的实例中,修改了id为5的文档标题,并删除了content内容,执行完毕之后,结果如何呢?
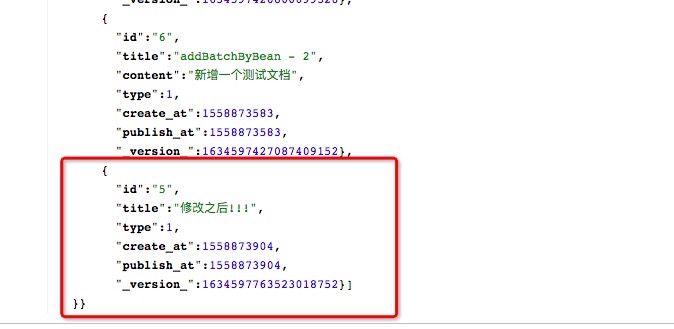
- title被替换
- content没有了
到这里就有个疑问了,对于调用而言,怎么保证是修改还是新增呢?
- 这里主要是根据id来判断,这个id类似db中的唯一主键,当我们没有指定id时,会随机生成一个id
- 如果存在相同的id,则修改文档;如果不存在,则新增文档