
相关博文:
维持计数时间窗口数据结构的设计
I. 背景
有这么一个场景,我需要维护每个商品在3min, 10mn, 1h, 6h, 24h这几个时间窗口内的贸易总额,那么可以怎么实现?
问题拆解:
- 每个商品,对应多个时间窗口
- 商品可能很多,因此时间窗口的量可能很大
- 时间窗口的数据为总数,因此不需要记录每个订单的情况,只需要维护一个交易总额即可
- 热点数据,可能每分钟都有很多的成交
- 冷门数据,可能一天都没有几笔成交
说明:
这个例子只是为了加以理解主题中设计的数据结构的背景,当然可能不是特别合适,因为实际的交易系统中,每笔订单都是会存下来的,而我们单独的剥离处这个数据结构,假设这些数据都不存储,我只关系其中的价格,然后维护n个时间窗口的总额实时更新
II. 数据结构设计
1. 基于队列的实现方式
基于队列的方式,可算是比较简单的一种实现了,我们依然以一分钟为一个时间片为例进行说明,每次往队列尾添加新的时间片数据;一个轮询的线程不断的取出队列尾部的时间片数据,并判断是否可以从时间窗口中减去,如果可以则直接减,否则等待下一次轮询,对应的数据结构如下
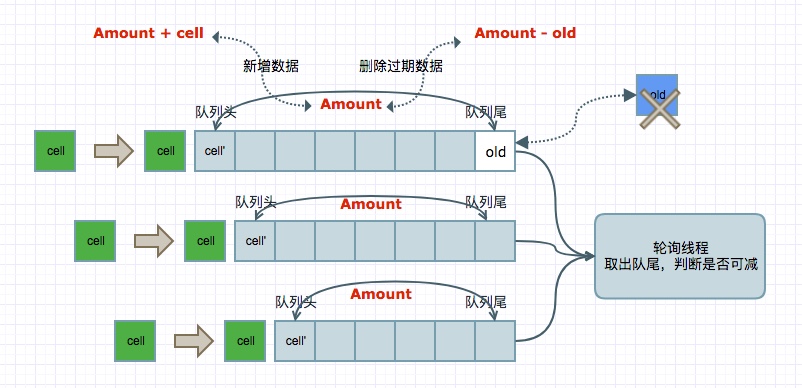
a. 数据结构说明
基本结构:
- 每个时间窗口维护一个队列
- 每个时间片为队列中的一个元素
大致逻辑:
- 新来一条数据,在队列头直接插入,并同步更新时间窗口的总数 (amount + cell)
- 一个定时任务,从对列尾部取出数据,判断是否过期,若是,则更新时间窗口总数(amount - old),并再从队列尾部取出一条判断;若未过期,则不做任何处理
b. 优缺点
优点:
- 实现简单
- 逻辑清晰
缺点:
- 每个时间窗口都需要维护一个队列,额外存储开销,同时也会带来更多地读写io
- 并发安全问题(同时删除和新增数据时,保证总数不会出现并发问题)
- 潜在的数据不一致问题
- 如在更新3min, 10min, 1h的时间窗口的队列数据时,3min, 10min的更新成功,但是1h的更新失败,从而导致1h的总量可能小于1min, 10min
2. 基于大Map的实现方式
相比较于队列中每个时间窗口维护一个队列,这里则改成对所有的时间窗口维护一个数据结构,这样维护3min, 10min, 1h等时间窗口的数据,则可以根据这个大的数据结构来计算得出
a. 大数组
如果这个数据结构使用Array,会有什么问题?
由于某些时间片段可能没有数据
- 如果维护定长的列表,则可能导致大量的空元素
- 如果维护紧凑的数组,则定期删除过期数据,要么遍历数组,要么记录上次删除的偏移量
b. 大Map
采用map结构来记录每个时间片的数据,正好可以解决上面数组面临大量空数据的问题,当然一个缺陷就是没法一次获取多个时间片数据,其对应的数据结构如下
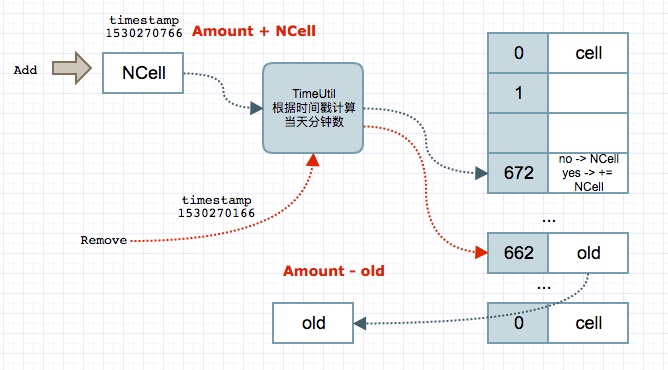
根据这个结构,给出大致的原理:
- 新增数据时,根据时间戳,定位到map中对应的kv数据,如果存在并没有过期,则累加,否则插入新的数据;总数实时更新
- 定时任务,删除数据时,根据需要删除的时间戳,定位到map中的kv数据,从总数中删除旧的数据
c. 对比
- 相比较于持有空数据的数组而言,map结构开销更小的同时,定位旧数据难度没有增加
- 相比较于紧凑型数组而言,定位旧数据更加便捷,不需要遍历
III. 方案设计分析
选择前面的第二种数据结构作为时间窗口的底层数据存储,即采用大Map的方式保存历史时间片段的数据,基于此进行时间窗口的统计
0. 实时计算
这个可算是最容易想到了,既然已经保存了所有的历史数据,那么想实现哪些时间窗口的数据,就拿哪些数据进行遍历计算即可
a. 举例说明
保存一天的数据,每分钟作为一个时间片段,我们根据时间戳,在当天的分钟数,作为Map中的Key
即时间 2018-07-01 00:00:00 对应的key为0, 2018-07-01 01:03:00 对应的key为 1 * 60+ 3 = 63
若当前时间为 2018-07-01 12:03:01, 则3min的时间窗口数据为:
- 02分时间片段 + 01分时间片段 + 00分时间片段
- 即:
map.get(12 * 60 + 2) + map.get(12 * 60 + 1) + map.get(12 * 60 + 0)
b. 优缺点
优点:
- 逻辑清晰,实现简单,容易理解
缺点:
- 每次都进行计算,当维护的时间窗口较多时,性能开销较大
1. 定时新增和减数据
相比第一种每次进行实时全量计算,下面两个则表示增量计算,即根据当前的时间窗口的值,加上最新的数据并减去过期的数据,从而更新时间窗口的值
这种方案的选择,算是比较容易理解和实现的,简单来说,就是有一个定时器,每隔一段时间加上最新的一个(或多个)时间片段的数据,并移除过期的时间片段
a. 实例说明
假设下载有一个3min, 10min, 1h的时间窗口,以其中3min中的时间窗口进行说明
- 时间窗口内的数据对应的时间段为
2018-07-01 12:00:00 - 2018-07-01 12:03:00 - 即时间窗口的数据为
map.get(12 * 60 + 2) + map.get(12 * 60 + 1) + map.get(12 * 60 + 0)
根据定时任务,实现增量加减逻辑:
- 若现在是 12:05:12,则增量加
map.get(12 * 60 + 4), 增量减map.get(12 * 60 + 0) - 若现在是 12:06:12,则增量加
map.get(12 * 60 + 4) + map.get(12 * 60 + 5), 增量减map.get(12 * 60 + 0) + map.get(12 * 60 + 1)
b. 优缺点
优点:
- 不需要遍历计算,只需维护增量变动,性能开销小
- 同时执行加减,逻辑相对简单
- 没有并发问题
缺点:
- 需要维护时间窗口中最新一条数据和最旧一条数据的时间戳,在进行增量时,根据这两个时间戳计算需要增量的时间片数据
- 数据阻塞导致数据问题,如假设当前为06分,计算时间窗口时将05分时间片的数据计算进去了,但是此时已然有一些05分的数据还没有写到对应的时间片,此时就会导致数据不一致问题
- 即加入的05分时间片数据为部分数据;而减去时05分时间片数据可能为完整数据
- 数据少加,从而导致最终时间窗口的数据可能为负数
2. 实时增,定时减过期数据
如果前面的方案理解了,这里也就好懂了,主要是为了解决上面一种方案中数据阻塞导致错误减的问题,我们采用实时加数据的方案
a. 方案解释说明
前面的说明,可能漏掉了一点,即Map结构的维护逻辑,这里一并给出说明
每次新来一条数据Record时,执行以下步骤
- 计算在Map中的位置index,取出对应的时间片数据 data
- 若data未空,或data为过期数据,则data=record并写回Map; 否则 data += recorde 写回Map
- 时间窗口数据window,判断record对于window是否为有效数据(即判断record对应的时间戳与window上次减数据的时间戳,若小,则表示record数据window已经减过的时间片,表示无效)
- 有效数据,则 window += record
- 无效数据,则丢弃
定时任务实现数据减:
- 根据当前时间戳,计算需要删除的时间戳 newRemove
- 获取时间窗口中,上次删除数据对应的时间戳 oldRemove
- 则需要删除的数据为
[oldRemove + 1min, newRemove]
对这个方案一句话进行说明:
没来一个数据,实时的加到时间窗口中;然后每分钟定时的把过期数据删掉
b. 分析
这个方案相对前面两个而言,会复杂一些,首先最明显的问题就是并发安全问题和如何保证数据的增量加和减不会有问题
并发问题
- 增量加和定时减,属于两个线程,所以需要同步机制保证不会出现时间窗口的并发修改问题
- 可采取的方案无非CAS和锁同步
- cas性能更优,但需要存储层支持,或自己实现乐观锁
- 锁同步,对性能有影响,但实现简单
数据一致性问题
- 需要考虑几个极端的情况下,数据会不会准确
- 数据堆积,导致新增的数据不会实时最新的,即这个数据落后于时间窗口的跨度
- 定时减数据时出现异常的case,在下次恢复时如何保证不会重复减
- 如大Map的长度为一天1440min时,则当数据出现跨天时,map中数据可能为过期数据时,需要保证不会删除过期数据,也不会加入过期数据
注意:
此外这种方法,与前面几种对比而言,并不是维护一个完整的时间窗口内的数据,因为属于实时增加,所以一个3min的时间窗口,可能是前面3(or2)分钟+最近一分钟内的实时数据
IV. 总结
上面介绍了几种方法,当然对于设计阶段的描述,其实最好的是能做一个动图,来演示整个过程,但是能力有限,只能尽力用语言进行描述了,可能不是特别好理解,下面进行抓重点,对上面的整片内容进行简洁说明
1. 数据结构
| 方案 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| 队列 | 每个时间窗口维护一个队列,由一个线程不断的从队列尾获取过期数据,并从时间窗口中减掉,从而维护时间窗口总数 | 简单容易实现 | 存储开销大 |
| map | Map结构,保存所有的时间窗口的历史数据,由一个线程,根据不同的时间窗口,计算需要删除数据在Map中对应的位置,从而取出数据并删掉 | 开销小,实现相对容易 | 批量获取过期数据需要存储端支持(如redis支持hmget, 而内存map则不行) |
2. 方案篇
| 方案 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| 实时计算 | 每个时间窗口的总数,直接根据历史数据计算得出 | 简单易理解 | 性能开销大 |
| 定时增减 | 一个定时任务,增加最新时间片的数据和删除过期的时间片数据 | 实现简单,无并发问题 | 数据一致性问题,数据阻塞可能导致总数为负 |
| 实时增,定时减 | 新来数据,直接加时间窗口;定时任务减过期数据 | 一致性高,性能相对高 | 实现复杂,需要注意并发问题和数据一致性问题 |
V. 其他
1. 一灰灰Blog: https://liuyueyi.github.io/hexblog
一灰灰的个人博客,记录所有学习和工作中的博文,欢迎大家前去逛逛
2. 声明
尽信书则不如,已上内容,纯属一家之言,因个人能力有限,难免有疏漏和错误之处,如发现bug或者有更好的建议,欢迎批评指正,不吝感激
- 微博地址: 小灰灰Blog
- QQ: 一灰灰/3302797840
3. 扫描关注


