第一篇实现一个最简单爬虫
准备写个爬虫, 可以怎么搞?
I. 使用场景 先定义一个最简单的使用场景,给你一个url,把这个url中指定的内容爬下来,然后停止
一个待爬去的网址(有个地方指定爬的网址)
如何获取指定的内容(可以配置规则来获取指定的内容)
II. 设计 & 实现 1. 基本数据结构
一个配置项,包含塞入的 url 和 获取规则
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @ToString public class CrawlMeta @Getter @Setter private String url; @Setter private Set<String> selectorRules; public Set<String> getSelectorRules () return selectorRules != null ? selectorRules : new HashSet<>(); } }
CrawlResult
抓取的结果,除了根据匹配的规则获取的结果之外,把整个html的数据也保存下来,这样实际使用者就可以更灵活的重新定义获取规则
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import org.jsoup.nodes.Document;@Getter @Setter @ToString public class CrawlResult private String url; private Document htmlDoc; private Map<String, List<String>> result; }
说明:这里采用jsoup来解析html
2. 爬取任务
爬取网页的具体逻辑就放在这里了
一个爬取的任务 CrawlJob,爬虫嘛,正常来讲都会塞到一个线程中去执行,虽然我们是第一篇,也不至于low到直接放到主线程去做
面向接口编程,所以我们定义了一个 IJob 的接口
IJob.java这里定义了两个方法,在job执行之前和之后的回调,加上主要某些逻辑可以放在这里来做(如打日志,耗时统计等),将辅助的代码从爬取的代码中抽取,使代码结构更整洁
1 2 3 4 5 6 7 8 9 10 11 12 13 public interface IJob extends Runnable void beforeRun () void afterRun () }
AbstractJob因为IJob 多了两个方法,所以就衍生了这个抽象类,不然每个具体的实现都得去实现这两个方法,有点蛋疼
然后就是借用了一丝模板设计模式的思路,把run方法也实现了,单独拎了一个doFetchPage方法给子类来实现,具体的抓取网页的逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public abstract class AbstractJob implements IJob public void beforeRun () } public void afterRun () } @Override public void run () this .beforeRun(); try { this .doFetchPage(); } catch (Exception e) { e.printStackTrace(); } this .afterRun(); } public abstract void doFetchPage () throws Exception }
SimpleCrawlJob一个最简单的实现类,直接利用了JDK的URL方法来抓去网页,然后利用jsoup进行html结构解析,这个实现中有较多的硬编码,先看着,下面就着手第一步优化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 @Getter @Setter public class SimpleCrawlJob extends AbstractJob private CrawlMeta crawlMeta; private CrawlResult crawlResult; public void doFetchPage () throws Exception URL url = new URL(crawlMeta.getUrl()); HttpURLConnection connection = (HttpURLConnection) url.openConnection(); BufferedReader in = null ; StringBuilder result = new StringBuilder(); try { connection.setRequestProperty("accept" , "*/*" ); connection.setRequestProperty("connection" , "Keep-Alive" ); connection.setRequestProperty("user-agent" , "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)" ); connection.connect(); Map<String, List<String>> map = connection.getHeaderFields(); for (String key : map.keySet()) { System.out.println(key + "--->" + map.get(key)); } in = new BufferedReader(new InputStreamReader( connection.getInputStream())); String line; while ((line = in.readLine()) != null ) { result.append(line); } } finally { try { if (in != null ) { in.close(); } } catch (Exception e2) { e2.printStackTrace(); } } doParse(result.toString()); } private void doParse (String html) Document doc = Jsoup.parse(html); Map<String, List<String>> map = new HashMap<>(crawlMeta.getSelectorRules().size()); for (String rule: crawlMeta.getSelectorRules()) { List<String> list = new ArrayList<>(); for (Element element: doc.select(rule)) { list.add(element.text()); } map.put(rule, list); } this .crawlResult = new CrawlResult(); this .crawlResult.setHtmlDoc(doc); this .crawlResult.setUrl(crawlMeta.getUrl()); this .crawlResult.setResult(map); } }
4. 测试
上面一个最简单的爬虫就完成了,就需要拉出来看看,是否可以正常的工作了
就拿自己的博客作为测试网址,目标是获取 title + content,所以测试代码如下
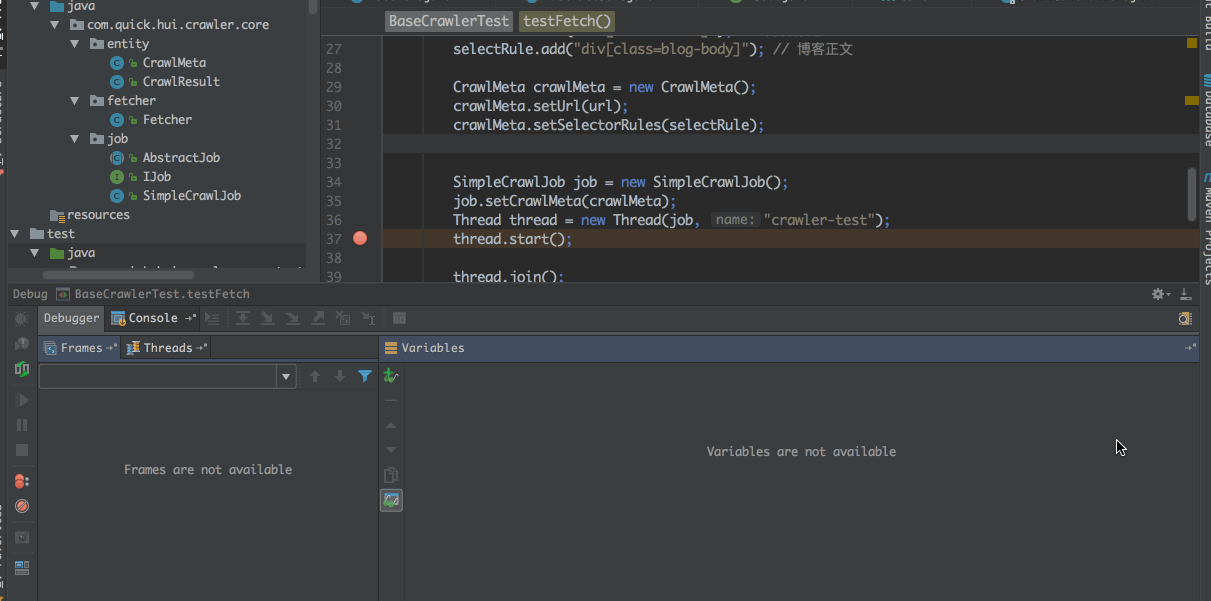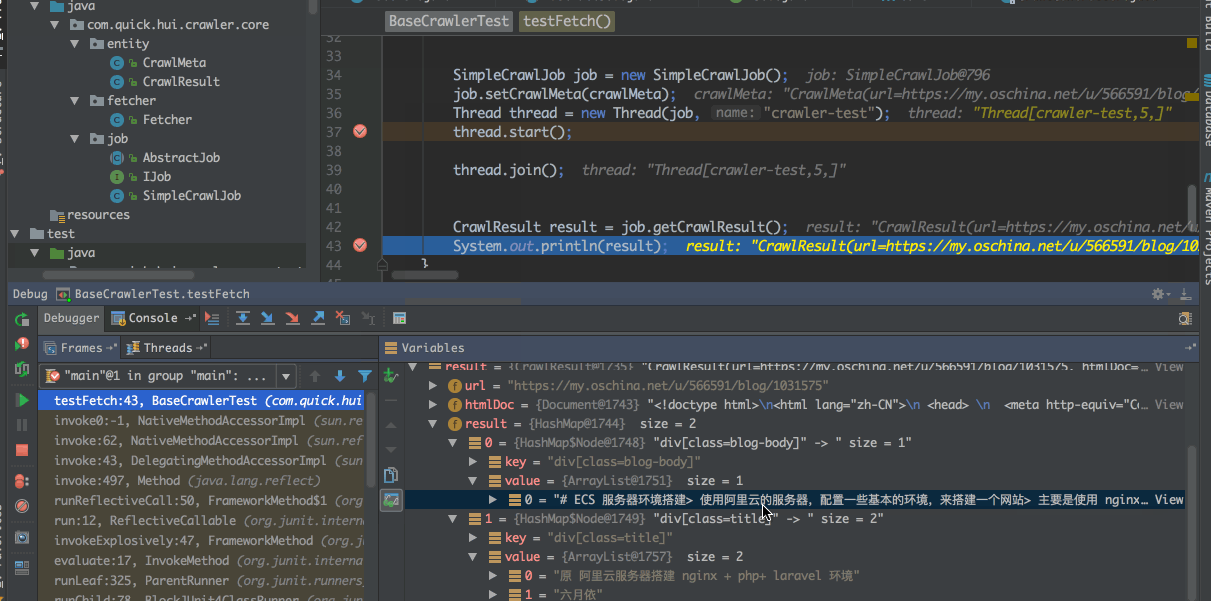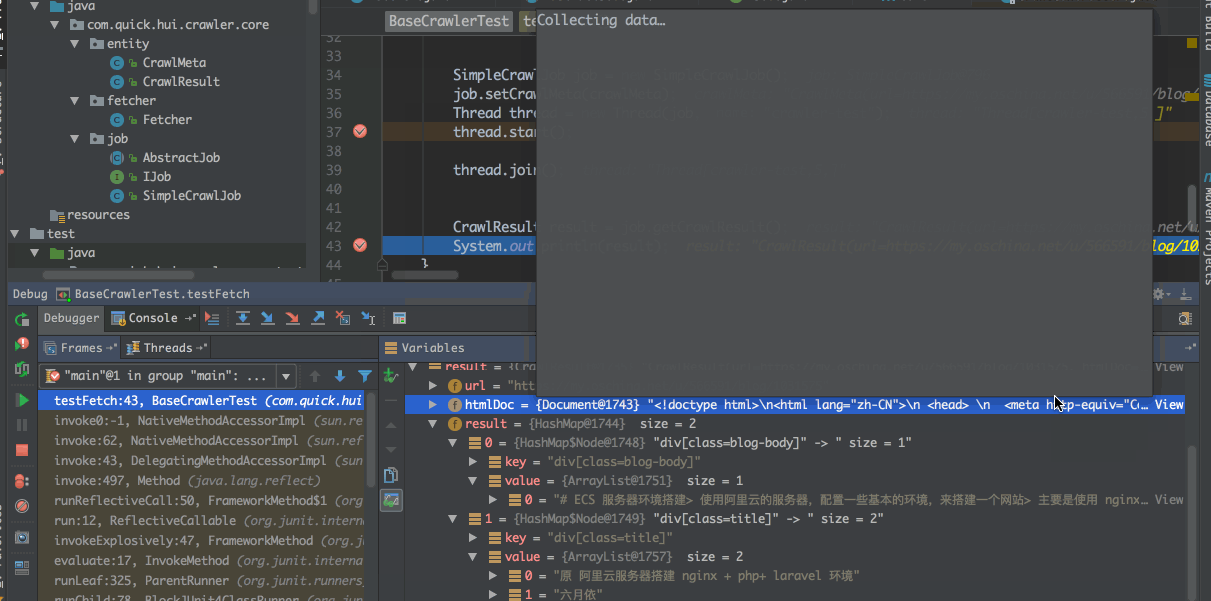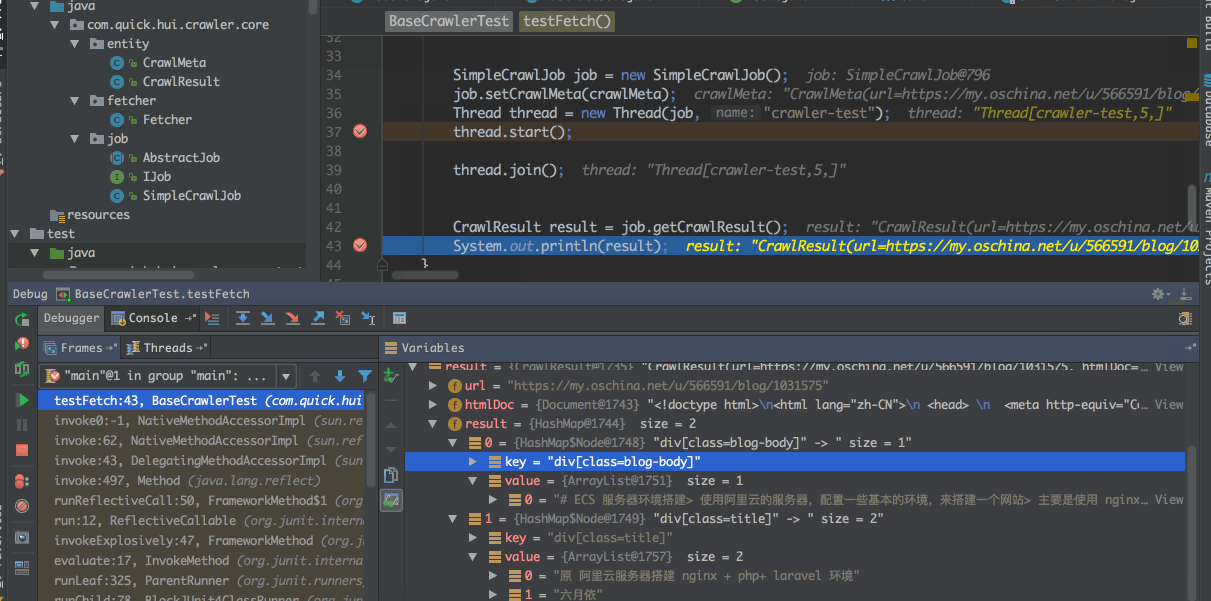
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @Test public void testFetch () throws InterruptedException String url = "https://my.oschina.net/u/566591/blog/1031575" ; Set<String> selectRule = new HashSet<>(); selectRule.add("div[class=title]" ); selectRule.add("div[class=blog-body]" ); CrawlMeta crawlMeta = new CrawlMeta(); crawlMeta.setUrl(url); crawlMeta.setSelectorRules(selectRule); SimpleCrawlJob job = new SimpleCrawlJob(); job.setCrawlMeta(crawlMeta); Thread thread = new Thread(job, "crawler-test" ); thread.start(); thread.join(); CrawlResult result = job.getCrawlResult(); System.out.println(result); }
代码演示示意图如下
从返回的结果可以看出,抓取到的title中包含了博客标题 + 作着,主要的解析是使用的 jsoup,所以这些抓去的规则可以参考jsoup的使用方式
III. 优化
上面完成之后,有个地方看着就不太舒服,doFetchPage 方法中的抓去网页,有不少的硬编码,而且那么一大串看着也不太利索, 所以考虑加一个配置项,用于记录HTTP相关的参数
可以用更成熟的http框架来取代jdk的访问方式,维护和使用更加简单
仅针对这个最简单的爬虫,我们开始着手上面的两个优化点
1. 改用 HttpClient 来执行网络请求 使用httpClient,重新改上面的获取网页代码(暂不考虑配置项的情况), 对比之后发现代码会简洁很多
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public void doFetchPage () throws Exception HttpClient httpClient = HttpClients.createDefault(); HttpGet httpGet = new HttpGet(crawlMeta.getUrl()); HttpResponse response = httpClient.execute(httpGet); String res = EntityUtils.toString(response.getEntity()); if (response.getStatusLine().getStatusCode() == 200 ) { doParse(res); } else { this .crawlResult = new CrawlResult(); this .crawlResult.setStatus(response.getStatusLine().getStatusCode(), response.getStatusLine().getReasonPhrase()); this .crawlResult.setUrl(crawlMeta.getUrl()); } }
这里加了一个对返回的code进行判断,兼容了一把访问不到数据的情况,对应的返回结果中,新加了一个表示状态的对象
CrawlResult
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private Status status;public void setStatus (int code, String msg) this .status = new Status(code, msg); } @Getter @Setter @ToString @AllArgsConstructor static class Status private int code; private String msg; }
然后再进行测试,结果发现返回状态为 403, 主要是没有设置一些必要的请求参数,被拦截了,手动塞几个参数再试则ok
1 2 3 4 HttpGet httpGet = new HttpGet(crawlMeta.getUrl()); httpGet.addHeader("accept" , "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8" ); httpGet.addHeader("connection" , "Keep-Alive" ); httpGet.addHeader("user-agent" , "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" );
2. http配置项
显然每次都这么手动塞入参数是不可选的,我们有必要透出一个接口,由用户自己来指定一些请求和返回参数
首先我们可以确认下都有些什么样的配置项
请求方法: GET, POST, OPTIONS, DELET …
RequestHeader: Accept Cookie Host Referer User-Agent Accept-Encoding Accept-Language … (直接打开一个网页,看请求的hedaers即可)
请求参数
ResponseHeader: 这个我们没法设置,但是我们可以设置网页的编码(这个来fix中文乱码比较使用)
是否走https(这个暂时可以不考虑,后面讨论)
新增一个配置文件,配置参数主要为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 @ToString public class CrawlHttpConf private static Map<String, String> DEFAULT_HEADERS; static { DEFAULT_HEADERS = new HashMap<>(); DEFAULT_HEADERS.put("accept" , "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8" ); DEFAULT_HEADERS.put("connection" , "Keep-Alive" ); DEFAULT_HEADERS.put("user-agent" , "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" ); } public enum HttpMethod { GET, POST, OPTIONS, PUT; } @Getter @Setter private HttpMethod method = HttpMethod.GET; @Setter private Map<String, String> requestHeaders; @Setter private Map<String, Object> requestParams; public Map<String, String> getRequestHeaders () return requestHeaders == null ? DEFAULT_HEADERS : requestHeaders; } public Map<String, Object> getRequestParams () return requestParams == null ? Collections.emptyMap() : requestParams; } }
新建一个 HttpUtils 工具类,来具体的执行Http请求, 下面我们暂先实现Get/Post两个请求方式,后续可以再这里进行扩展和优化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 public class HttpUtils public static HttpResponse request (CrawlMeta crawlMeta, CrawlHttpConf httpConf) throws Exception switch (httpConf.getMethod()) { case GET: return doGet(crawlMeta, httpConf); case POST: return doPost(crawlMeta, httpConf); default : return null ; } } private static HttpResponse doGet (CrawlMeta crawlMeta, CrawlHttpConf httpConf) throws Exception SSLContextBuilder builder = new SSLContextBuilder(); builder.loadTrustMaterial(null , (x509Certificates, s) -> true ); HttpClient httpClient = HttpClientBuilder.create().setSslcontext(builder.build()).build(); StringBuilder param = new StringBuilder(crawlMeta.getUrl()).append("?" ); for (Map.Entry<String, Object> entry : httpConf.getRequestParams().entrySet()) { param.append(entry.getKey()) .append("=" ) .append(entry.getValue()) .append("&" ); } HttpGet httpGet = new HttpGet(param.substring(0 , param.length() - 1 )); for (Map.Entry<String, String> head : httpConf.getRequestHeaders().entrySet()) { httpGet.addHeader(head.getKey(), head.getValue()); } return httpClient.execute(httpGet); } private static HttpResponse doPost (CrawlMeta crawlMeta, CrawlHttpConf httpConf) throws Exception SSLContextBuilder builder = new SSLContextBuilder(); builder.loadTrustMaterial(null , (x509Certificates, s) -> true ); HttpClient httpClient = HttpClientBuilder.create().setSslcontext(builder.build()).build(); HttpPost httpPost = new HttpPost(crawlMeta.getUrl()); List<NameValuePair> params = new ArrayList<>(); for (Map.Entry<String, Object> param : httpConf.getRequestParams().entrySet()) { params.add(new BasicNameValuePair(param.getKey(), param.getValue().toString())); } httpPost.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8)); for (Map.Entry<String, String> head : httpConf.getRequestHeaders().entrySet()) { httpPost.addHeader(head.getKey(), head.getValue()); } return httpClient.execute(httpPost); } }
然后我们的 doFetchPage 方法将简洁很多
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public void doFetchPage () throws Exception HttpResponse response = HttpUtils.request(crawlMeta, httpConf); String res = EntityUtils.toString(response.getEntity()); if (response.getStatusLine().getStatusCode() == 200 ) { doParse(res); } else { this .crawlResult = new CrawlResult(); this .crawlResult.setStatus(response.getStatusLine().getStatusCode(), response.getStatusLine().getReasonPhrase()); this .crawlResult.setUrl(crawlMeta.getUrl()); } }
下一步 上面我们实现的是一个最简陋,最基础的东西了,但是这个基本上又算是满足了核心的功能点,但距离一个真正的爬虫框架还差那些呢 ?
另一个核心的就是:
爬了一个网址之后,解析这个网址中的链接,继续爬!!!
下一篇则将在本此的基础上,考虑如何实现上面这个功能点;写这个博客的思路,将是先做一个实现需求场景的东西出来,,可能在开始实现时,很多东西都比较挫,兼容性扩展性易用性啥的都不怎么样,计划是在完成基本的需求点之后,然后再着手去优化看不顺眼的地方
坚持,希望可以持之以恒,完善这个东西
IV. 其他 源码 项目地址: https://github.com/liuyueyi/quick-crawler
上面的分了两步,均可以在对应的tag中找到响应的代码,主要代码都在core模块下
第一步对应的tag为:v0.001
优化后对应的tag为:v0.002
相关博文 Quick-Crawel爬虫系列博文
一灰灰的个人博客,记录所有学习和工作中的博文,欢迎大家前去逛逛
声明 尽信书则不如,已上内容,纯属一家之言,因个人能力有限,难免有疏漏和错误之处,如发现bug或者有更好的建议,欢迎批评指正,不吝感激
扫描关注